Ошибка 504 gateway time out — что значит почему она возникает и как ее исправить?
Содержание:
- Inbound Call Error example
- For Inbound calls
- For Outbound calls
- Summary
- Как можно увидеть ошибку 504 Gateway Time out
- Больше способов увидеть ошибку 504 Gateway Time out
- What are Nginx Upstream Errors?
- Как исправить ошибку времени ожидания шлюза 504
- Как исправить ошибку 504?
- Nginx Upstream Errors – Top 6 reasons and solutions
- Outbound Call Error example
- Why is this happening?
Inbound Call Error example
Below is an entry in the istio-proxy sidecar log for an incoming request, where “UC” indicates “Upstream connection termination in addition to 503 response code“, which means that for some reason the connection between istio-proxy and its upstream container within the pod has been terminated.
There is also another type of response flag “UF“, indicates “Upstream connection failure in addition to 503 response code” — again for some reason istio-proxy was unable to connect to its upstream container within the pod.
"GET /service_a/v2.1/get?ids=123456 HTTP/1.1" 503 UC "-" "-" 0 95 11 - "-" "-" "bc6f9ba3-d8dc-4955-a092-64617d9277c8" "srv-a.xyz" "127.0.0.1:8080" inbound|80|http|srv-a.xyz.svc.cluster.local - 100.64.121.11:8080 100.64.254.9:35174 - "GET /service_b/v2.5/get?getIds=123456 HTTP/1.1" 503 UF "-" "-" 0 91 0 - "-" "-" "d0dbd0fe-90db-46d0-b614-7eaea3764f79" "srv-b.xyz.svc.cluster.local" "127.0.0.1:8080" inbound|80|http|srv-b.xyz.svc.cluster.local - 100.65.130.7:8080 100.64.187.3:53378 -
For Inbound calls
Ideally the istio-proxy within the pod should be able to handle the upstream connection close events by the localhost upstream server. However a simple workaround can resolve this issue until we understand whether or not this behaviour is an issue or by design in later versions of Istio. The workaround solution for inbound calls is simple, just set infinite request pipelining on a connection with only an idle timeout for connection recycling.
for Tomcat app server maxKeepAliveRequests = -1for Finagle app server # Don't set any value, then it defaults to unbounded. maxLifeTime(timeout: Duration)
In the past, within a Kubernetes cluster the in-cluster request routing was through ServiceIP (<service_name>.<namespace>) that worked at layer 3/4, which does only connection load balancing. Hence it was required to close the connections after serving a certain number of requests to correctly distribute requests across multiple instances evenly. Though frequent connection closing impacts latencies, it is very much needed when compared to having an uneven request load across instances which causes the bigger problem of loads being too large on some instances. With Istio, there is no need for connection recycling as the istio-proxy works at layer 7 and does request load balancing using persistent connections and this also improves latencies. In the case of layer 7 request load balancing, the only time a connection is closed is on idle timeout and both server and client applications must implement idle connection evictions.
For Outbound calls
Now we know the reason for the 503 error when using istio-proxy for outbound calls, which require performing a DNS resolution on the external service host periodically. There are a few options to resolve this
- Don’t use persistent connections for outbound calls — This will resolve the issue but is not scalable when you have too many requests per second. Also a code change is needed for an existing application that uses persistent connections through a httpclient connection pool.
- Perform DNS resolutions periodically — Change your application to periodically close the connection and open a fresh connection to perform a DNS resolution, this solution works fine but requires code changes to the existing application.
- Configure Istio to perform DNS resolutions periodically — This is the best solution that can be implemented very easily without changing the application code. Istio traffic routing allows you to configure ServiceEntry and VirtualService for routing calls to external services, so by configuring these for the external services we can avoid 503 issues.
- Configure Istio to increase Response Timeout — In order to avoid 504 errors for response timeouts and to accommodate longer than 15 second response timeout for upstream service calls, configure the timeout value within the VirtualService as shown below
The following example ServiceEntry and VirtualService instructs istio-proxy to perform DNS resolution periodically and the response timeout set to 30s instead of the default 15s.
ServiceEntry
apiVersion: networking.istio.io/v1alpha3kind: ServiceEntrymetadata: name: ext-service-sespec: hosts: - external.service.com location: MESH_EXTERNAL ports: - number: 80 name: service-http protocol: HTTPresolution: DNS
VirtualService
apiVersion: networking.istio.io/v1alpha3kind: VirtualServicemetadata: name: ext-service-vsspec: hosts: - external.service.comhttp:- timeout: 30s route: - destination: host: external.service.com weight: 100
The above ServiceEntry DNS resolution configures 300 second DNS refresh interval by default, which can be seen in the istio-proxy config dump.
"dns_refresh_rate": "300s", "dns_lookup_family": "V4_ONLY", "load_assignment": { "cluster_name": "outbound|80||external.service.com", "endpoints": , "load_balancing_weight": 1 } ] }
This DNS refresh time is too long for most of the applications in AWS clusters, and also as per the AWS best practices and guidance the DNS refresh rate must be set to as low as 60 seconds. The DNS refresh rate configuration parameter — “global.proxy.dnsRefreshRate” — is a global setting for the istio-proxy which defaults to 300 seconds, and changing this parameter affects the entire mesh so care must be taken when changing this value to a common value that is suitable for all apps and services in the mesh. Your Istio platform team should review and make the necessary changes for the DNS refresh rate.

Summary
So, with istio-proxy sidecar added to your applications, a 5xx error means there could be a number of reasons which must be carefully analysed by going through application metrics, upstream service metrics, istio-proxy logs and Istio configuration. It may also need enabling istio-proxy debug/trace logs and capturing network packets using tcpdump in the lab environment for further investigation.
It is important to setup appropriate ServiceEntry and VirtualService Istio configuration and server-side connection keep-alive configuration, as mentioned above, for resolving the http 503 and 504 errors for upstream service calls.
Analyses like these can be time consuming and require a wide range of skills to be applied, we in the Reliability Engineering team feel it’s helpful to the community to report our results in detail so that others encountering these issues can gain the benefit of our investigations. I hope you find this analysis and the explanations useful.
Update: At the time of writing this blog the Istio version used was 1.2.10. Though most of the points discussed in this blog may be applicable to other Istio versions too but some default values or configuration mentioned above may not mirror latest Istio version docs.
Как можно увидеть ошибку 504 Gateway Time out
Отдельным сайтам разрешено настраивать отображение ошибки Gateway Timeout. Вот несколько распространенных способов вывода подобной ошибки:
504 Gateway Timeout HTTP 504 504 ERROR Gateway Timeout (504) HTTP Error 504 - Gateway Timeout Gateway Timeout Error
Ошибка 504 Gateway Time out появляется внутри окна браузера, как обычная веб-страница. На ней могут быть знакомые верхние и нижние колонтитулы сайта и красивое английское сообщение. Также подобная ошибка может отображаться на полностью белой странице с большой цифрой 504 вверху. Это одно и то же сообщение, независимо от того, как сайт показывает его вам.
Помните, что ошибка 504 Gateway Time out и 502 Bad Gateway nginx может появиться в любом браузере, операционной системе и на любом устройстве.
Больше способов увидеть ошибку 504 Gateway Time out
Ошибка Gateway Timeout при получении в Windows Update генерирует код ошибки 0x80244023 или сообщение WU_E_PT_HTTP_STATUS_GATEWAY_TIMEOUT.
В программах на базе Windows, которые изначально обращаются к интернету, ошибка 504 может отображаться в небольшом диалоговом окне или окне с ошибкой HTTP_STATUS_GATEWAY_TIMEOUT и/или сообщение The request was timed out waiting for a gateway (истекло время ожидания запроса для шлюза).
Менее распространенная ошибка 504 — это Gateway Time-out: The proxy server did not receive a timely response from the upstream server (прокси-сервер не получил своевременного ответа от вышестоящего сервера), но поиск и устранение неисправностей (указанных выше) продолжается.
What are Nginx Upstream Errors?
With reverse proxy, it accepts a request from the client, forwards it to Upstream server(server that can complete the request), and returns the server’s response to the client.
Nginx upstream errors arise while the proxy server receive an invalid response or no response from the origin server.
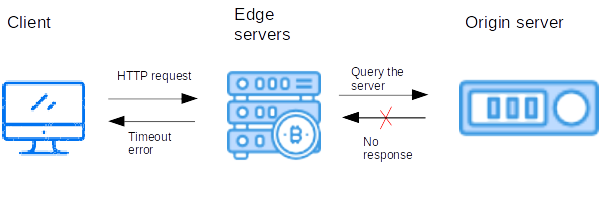
Visitors will see different variations of these errors like:
502 bad gateway 502 bad gateway nginx 502 Proxy error 504 Gateway Timeout HTTP 504 Gateway Timeout
These messages are cryptic.
So, many webmasters look at their error log:
2018/11/01 18:15:02 1713#0: *1 upstream timed out (110: Connection timed out) while connecting to upstream, client: xx.xx.xxx.xxx, server: , request: "GET / HTTP/1.1", upstream: "http://xx.xx.xx.xx:8082/", host: "xx.xx.xx.xx"
You can see that something is messed up but not sure where to start.
That’s where you need an expert to figure it out quickly and fix it permanently.
Today, let’s discuss the various reasons for nginx upstream errors and how our Dedicated Server Administrators fix them.
Как исправить ошибку времени ожидания шлюза 504
Повторите попытку веб-страницы, нажав кнопку обновления / перезагрузки, нажав клавишу F5 или еще раз попробовав URL из адресной строки.
Даже несмотря на то, что ошибка 504 Gateway Timeout сообщает об ошибке вне вашего контроля, эта ошибка может быть только временной.
Перезагрузите все ваши сетевые устройства . Временные проблемы с вашим модемом, маршрутизатором , коммутаторами или другим сетевым оборудованием могут быть причиной проблемы 504 Gateway Timeout, которую вы видите
Просто перезагрузка этих устройств может помочь.
В то время как порядок включения выключения этих устройств не важно, порядок включения их обратно на это. В общем, вы хотите включить устройства извне
Если вы не уверены, что это значит, просмотрите ссылку в начале этого шага для получения полного руководства.
Проверьте настройки прокси-сервера в вашем браузере или приложении и убедитесь, что они верны. Неправильные настройки прокси могут привести к 504 ошибкам.
Настройки прокси в Windows 10.
Большинство компьютеров вообще не имеют настроек прокси, поэтому, если у вас пусто, просто пропустите этот шаг.
Измените DNS-серверы , особенно если все устройства в вашей сети получают одинаковую ошибку. Возможно, ошибка 504 Gateway Timeout, которую вы видите, вызвана проблемой с DNS-серверами, которые вы используете.
Если вы ранее не меняли их, DNS-серверы, которые вы сейчас настроили, вероятно, автоматически назначаются вашим Интернет-провайдером . Другие DNS-серверы доступны для вашего использования, которые вы можете выбрать. Смотрите наш список бесплатных и общедоступных DNS-серверов .
Если до этого момента ничего не получалось, возможно, лучше всего связаться с веб-сайтом. Есть большая вероятность, что администраторы сайта уже работают над устранением основной причины ошибки 504 Gateway Timeout, при условии, что они знают об этом, но нет ничего плохого в том, чтобы связываться с ними.
Посетите нашу страницу контактной информации о сайте, чтобы узнать, как связаться с популярными сайтами. На большинстве крупных сайтов есть учетные записи социальных сетей, которые они используют для поддержки своих услуг, а на некоторых даже есть номера телефонов и адреса электронной почты.
Если он начинает выглядеть так, как будто веб-сайт выдает ошибку 504 для всех, поиск в Twitter в режиме реального времени информации об отключении сайта часто оказывается полезным. Лучший способ сделать это — поиск #websitedown в Twitter. Например, если Facebook может быть недоступен, поиск #facebookdown .
Обратитесь к вашему интернет-провайдеру. Вероятно, что после того, как вы выполнили все описанные выше действия по устранению неполадок, тайм-аут шлюза 504, который вы видите, является проблемой, вызванной проблемой сети, за которую отвечает ваш провайдер.
Возвращайся позже. На данный момент вы исчерпали все свои возможности, и ошибка 504 Gateway Timeout находится либо в руках сайта, либо у вашего интернет-провайдера для исправления. Проверяйте сайт регулярно. Нет сомнений, он скоро снова начнет работать.
Как исправить ошибку 504?
Слишком большое количество пользователей
В этом случае обычно помогает увеличение ресурсов сервера, на котором находится ваш сайт. Т.е. вам нужно попытаться сменить тарифный план, задуматься о покупке виртуального выделенного сервера, или же арендовать физический сервер. В любом случае, сначала проконсультируйтесь с технической поддержкой хостинг-провайдера, а потом уже принимайте решение.
Неправильная работа сайта
В этом случае нужно оптимизировать сайт, причем таким образом, чтобы работа скриптов укладывалась в отведенное время. Если для оптимизации нет возможности, то может помочь изменение параметра, который отвечает за максимальное время ожидания работы скрипта. Для этого в файле .htaccess нужно написать:
php_value max_execution_time N
Где N — это время ожидания в секундах, обычно по умолчанию оно равно 30 секунд. Но такая процедура помогает не у всех хостинг-провайдеров, и в таком случае следующим Вашим шагом должно стать обращение в службу поддержки или же смена хостинг-провайдера.
Юзеры ( 5 ) оценили на 4.0 из 5
Настоятельно рекомендуем не покупать слишком дешевый хостинг! Как правило с ним очень много проблем: сервер иногда не работает, оборудование старое, поддержка долго отвечает или не может решить проблему, сайт хостера глючит, ошибки в регистрации, оплате и т.д.
Также мы собрали тарифы от тысяч хостеров, чтобы вы могли выбрать хостинг по конкретной цене.
Облачный хостинг — распределение нагрузки на несколько серверов, если сервер с вашим сайтом перегружен или не работает. Это гарантия того что пользователи в любом случае смогут видеть ваш сайт. Но это дорогая, более сложная опция, которую предоставляют далеко не все провайдеры.
Виртуальный хостинг — подходит для большинства проектов начального уровня с посещаемостью до 1000 человек в сутки. В таком хостинге мощность сервера делится между несколькими хостинговыми аккаунтами. Услуга проста в настройке даже для новичков.
VPS — подходит для более сложных проектов с достаточно большой нагрузкой и посещаемостью до 10000 человек в сутки. Здесь мощность сервера фиксированная для каждого виртуального сервера, при этом сложность настройки увеличивается.
Выделенный сервер — нужен для очень сложных и ресурсоемких проектов. Для вас выделяют отдельный сервер,мощность которого будете использовать только вы. Дорого и сложно настраивать.
Размещение и обслуживание вашего собственного сервера в дата-центре хостинга — это не очень популярная услуга и требуется в исключительных случаях.
CMS — это система управления контентом сайта. Хостеры стараются для каждой из них делать отдельный тариф или упрощать установку. Но в целом это больше маркетинговые ходы, т.к. у большинства популярных CMS нет специальных требований к хостингу, а те что есть — поддерживаются на большинстве серверов.
Тестовый период — предоставляется хостером бесплатно на 7-30 дней, чтобы вы могли удостовериться в его качестве.
Moneyback — период на протяжении которого хостер обязуется вернуть деньги, если вам не понравится хостинг.
Означает какая операционная система установлена на сервере хостинга. Мы рекомендуем размещать на серверах с Linux, если нет особых требований у разработчиков сайта.
Абузоустойчивый хостинг — компании, которые разрешают размещать практически любой контент, даже запрещенный (спам, варез, дорвеи, порнографические материалы). Такие компании не удаляют контент вашего веб-сайта при первой же жалобе (“абузе”).
Безлимитный хостинг — хостинг у которого отсутствуют лимиты на количество сайтов, БД и почтовых ящиков, трафик, дисковое пространство и т.д. Обычно это больше маркетинговый трюк, но можно найти что-то интересное для себя.
Безопасный хостинг — тот, где администрация постоянно обновляет ПО установленное на серверах, устанавливает базовую защиту от DDoS-атак, антивирус и файерволлы, блокирует взломанные сайты и помогает их «лечить».
Защита от DDOS — компании, которые предоставляют хостинг с защитой от DDoS-атак. Такие пакеты ощутимо дороже обычных, но они стоят своих денег, так как ваш сайт будет защищен от всех видов сетевых атак.
На языке программирования PHP и базах данных MySQL сейчас работает большинство сайтов. Они же поддерживаются практически всеми современными хостингами.
ASP.NET — платформа для разработки веб-приложений от Майкрософт.
От панели управления зависит ваше удобство в настройке хостингесайта.
Большинство качественных хостингов из нашего ТОПа используют удобные панели управления, поэтому рекомендуем больше внимания уделить другим параметрам при выборе.
Nginx Upstream Errors – Top 6 reasons and solutions
In our experience handling nginx upstream errors, we’ll see the major causes that we’ve come across.
1. High load on origin server
Heavy load spike cause services to not respond.
Hence, Nginx can’t communicate with the origin server and result in this error.
The most common reasons for load spikes are:
- Compromised server that sends malware or spam.
- Heavy website traffic(can be marketing, promotional etc.).
- Brute force attacks to exploit web applications.
- Application bugs that cause resource hogging and memory leakage.
How we fix?
Our Hosting Engineers first identify the resource that is being abused. Then we find out which service is abusing that resource.
At this point, we identify the user who owns the script or software for abusing the service.
2. Service downtime in origin server
Nginx depends on various services like apache, PHP-FPM, database services, etc. to run applications.
If any of these services crash, Nginx won’t get any data and result in errors.
How we fix?
The reasons for service failure can be traffic spikes, resource outages, DDOS attacks, disk errors and so on.
We’ll identify this reason and fix it.
If a backend service fails or doesn’t respond, we’ll kill all the dead processes and restart the service.
3. Firewall blocks a request
Firewall is the keystone of server security. If not configured properly, it can block legitimate requests or services.
By default, firewall block uncommon ports in the server.
If you have a new service(eg: Ruby) enabled in the server and it runs on a custom port, there can be chances that this port is blocked in the firewall.
Hence, Nginx can’t communicate with this service and lead to this error.
How we fix?
To fix it, we look at which port each service runs on using the command netstat.
If we find any service running on custom ports, we edit the firewall configuration to allow these custom ports.
4. Network problems
DNS issues, routing problems and ISP problems can lead to Nginx upstream errors.
If recent DNS changes were made, like changing nameservers, hosting servers, etc. it will take some time to propagate globally. The domain may be unroutable during this period.
Also, sometimes ISPs may block access to a particular site.
All these can lead to such errors.
How we fix?
We check the DNS connectivity of the domain using the command:
dig domain.com
Also, we access the domain from third-party proxy servers to identify if this error is specific to the customer.
If any DNS conflicts found, we will quickly correct it. If the issue is at ISP end, then this needs to be fixed at their end.
5. Server software timeouts
Nginx upstream errors can also occur when a webserver takes more time to complete the request.
By that time, the caching server will reaches its timeout values(timeout for the connection between proxy and upstream server).
Slow queries can lead to such problems.
How we fix?
We will fine tune the following Nginx timeout values in the Nginx configuration file.
Once the timeout values are added, need to reload nginx to save these parameters.
6. Application code bugs
If all other checks failed, it can be an error in your web application code.
Sometimes, your application code may be incompatible with the server version prompting this error to show up.
How we fix?
We will diagnose the issue by analyzing the application and web server logs.
Also, we review the software requirements of your application, re-configure the services to match the required version.
Outbound Call Error example
Below is an example error log message in one of the application pod’s istio-proxy sidecar logs, when the app is accessing an external service domain “external.service.com”, where the “UF” response flag next to HTTP 503 code indicates “Upstream connection failure in addition to 503 response code“, which is similar to the one seen above for inbound call, and means for some reason it was unable to establish a connection to the remote host.
"GET /External.WebService/v2/Ids HTTP/1.1" 503 UF "-" "-" 0 91 0 - "-" "Apache-HttpClient/4.5.5 (Java/11)" "c75a750d-9efd-49e7-a419-6ed97298b543" "external.service.com" "55.92.142.17:80" PassthroughCluster - 55.92.142.17:80 100.65.254.14:39140 -
Below are a few example error log messages for the upstream response timeout, where the “UT” response flag next to HTTP 504 code indicates “Upstream request timeout in addition to 504 response code“, here the istio-proxy waited up to 15000 milliseconds, before walking away (the 5th field from response flag highlighted in bold).
"POST /ext_svc/1111000222333/add?currency=GBP&locale=en_GB HTTP/1.1" 504 UT "-" "-" 150 24 15004 - "-" "Jersey/2.27 (HttpUrlConnection 11.0.4)" "7e9a9207-690f-45b1-b574-fc806b117a84" "testservice.prod.com" "10.186.199.78:80" PassthroughCluster - 10.186.199.78:80 100.65.161.7:37302 - "GET /api/1234567 HTTP/1.1" 504 UT "-" "-" 0 24 15001 - "-" "ABC.3.1.449" "4403f657-f324-4c60-befd-343a23e9520a" "apisvc.prod.com" "10.186.199.78:80" PassthroughCluster - 10.186.199.78:80 100.66.91.11:50288 -
Note: For TLS connections, without Istio mutual TLS (mTLS), there will not be any HTTP status codes nor UT/UC response flags reported in the proxy logs. This is due to TLS encryption which cannot be intercepted by istio-proxy unless mTLS is used.

Why is this happening?
In order to debug these issues it is necessary to use a combination of options such as manual tests while observing logs and error patterns, plus istio-proxy debug/trace logging and tcpdumps to capture the packets. All the data collected lead to the following conclusions.