15 best wayback machine alternatives 2021
Содержание:
- Правовой статус[править | править код]
- The Wayback Machine is a great archive of billions of webpages since the beginning of the web. But when it comes to reliably archiving screenshots of specific webpages, Stillio comes up as of the best Wayback machine alternative.
- Wayback Machine vs Stillio
- FAQ: Stillio vs Wayback Machine
- Detailed comparison
- Юридические проблемы с архивным контентом
- Ограничения[править | править код]
- Reasons for using the Wayback Downloader
- mydrop.io
- Page Freezer
- DomainTools
- Donation Process
- archive.md
- But What if a Page I want to See is not in the Archive?
- Method 2: using FTP
- r-tools.org
- Создание[править | править код]
Правовой статус[править | править код]
«Архив Интернета» не запрашивает разрешения на копирование веб-сайтов перед удалённым сбором данных, однако удаляет или ограничивает доступ к архивным материалам по запросу. Например, владельцам веб-сайтов предоставляется возможность «отказаться» от архивирования через стандартный файл robots.txt, который исключает веб-сайты из списка порталов для веб-краулеров. Однако из-за сохранения других данных «Архив Интернета» находится в уязвимом юридическом положении. Так, в 2005 году Wayback Machine оказался втянутым в спор о товарных знаках между компаниями Healthcare Advocates и Health Advocate. Последняя использовала Wayback Machine для доступа к веб-страницам Healthcare Advocates, датируемым 1999 годом, в попытке найти информацию, которая поддержала бы дело. В ответ Healthcare Advocates подала в суд как на Health Advocatt, так и на Архив, утверждая что архив нарушил Закон об авторском праве в цифровую эпоху. Впоследствии дело было урегулировано в досудебном порядке.
В 2002 году Архив удалил из своей системы ссылки на архивные копии портала Xenu.net, принадлежащего критику церкви Андреасу Хельдал-Лунду. Удаление произошло по требованию юристов Церкви Саентологии, заявивших, что владеют правом собственности на выдержки из документов Церкви, опубликованные на сайте.
The Wayback Machine is a great archive of billions of webpages since the beginning of the web. But when it comes to reliably archiving screenshots of specific webpages, Stillio comes up as of the best Wayback machine alternative.
Wayback Machine vs Stillio
With the increasing demand of web archiving, businesses are looking for a trusted solution which can offer customized solutions. The Wayback Machine is a great tool to look at how the web started and how it evolves over time. But it’s is not a reliable tool for archiving webpages. Not all pages are being captures with the Wayback Machine and you have no control over the pages they capture. Also, the Wayback Machine doesn’t capture webpages on a daily basis and the captures of the Wayback Machine are not always complete. Often images are missing or the HTML is misinterpreted resulting in awkward looking pages. These shortcomings make the Wayback Machine a great tool to browse the history of the web, but it’s not a great tool for archiving important webpages consistently. A trusted wayback machine alternative has become a need of many. That’s where Stillio comes into the scenario. Let’s understand this with a chart on why Stillio is a perfect Wayback Machine alternative.
FAQ: Stillio vs Wayback Machine
Both Stillio and Wayback Machine archive webpages and allow you to see past versions of a single webpage.
What is the main difference between Stillio and Wayback Machine?
Format — Stillio captures a full-size PNG screenshot of the web page, showing everything accurately: text, images, typography, video stills, graphs, and any other element. Wayback Machine archives pages including the images and CSS. When a dynamic page contains JavaScript, or other elements that require interaction with the originating host, the archive will not contain the original site’s functionality. This may lead to broken pages or missing visuals like graphics.
Interval — With Stillio you control the archiving frequency and settings yourself. Wayback Machine has no fixed capture frequency..
Pricing — Wayback Machine is a free service, Stillio is subscription based.
Wayback Machine: The archived webpages can be browsed on their public website.
Does Stillio provide archived versions of any website for free?
As Stillio is a paid service, only pages that are added to the accounts of users are archived.
So unlike Wayback Machine, Stillio does not provide a free and public archive of webpages.
Detailed comparison
ARCHIVAL PROCESS
Full size PNG screenshotsCapture everything accurately: text, images, typography, video stills, graphs, or any other element.
HTMLMainly text and images are archived. Dynamic content may be missing.
AD SUPPORT
Yes, Stillio captures website ads.
No, website ads are not supported.
ARCHIVE SCHEDULING
Fully customizableHourly, daily or weekly or any frequency to have screenshots captured.
UnknownNo fixed capture frequency.
AUTOMATED ARCHIVING
Yes
No
REMOTE STORAGE
Yes, both offline and automatic sync to cloud providers like Dropbox, Google Drive and Zapier.
No
DOWNLOAD SUPPORT
Yes, monthly zip download available.
No
No
GEO SPECIFIC SCREENSHOTS
Yes, see the countries we support.
No
PRICING
Starts from $29, Try for Free!
Free
Юридические проблемы с архивным контентом
Некоторые дела были возбуждены против Internet Archive специально за его усилия по архивированию Wayback Machine.
Саентология
В конце 2002 года Интернет-архив удалил из Wayback Machine различные сайты, критикующие Саентологию . В сообщении об ошибке говорилось, что это было ответом на «запрос владельца сайта». Позже выяснилось, что юристы Церкви Саентологии требовали удаления, а владельцы сайта не хотели, чтобы их материалы были удалены.
Healthcare Advocates, Inc.
В 2003 году компания Harding Earley Follmer & Frailey защитила клиента от спора о товарном знаке с помощью Archive’s Wayback Machine. Адвокаты смогли продемонстрировать недействительность требований истца на основании содержания их веб-сайтов за несколько лет до этого. Истец, Healthcare Advocates, затем внес поправки в свою жалобу, включив в нее Интернет-архив, обвинив организацию в нарушении авторских прав, а также в нарушениях Закона США » Об авторском праве в цифровую эпоху» и Закона о компьютерном мошенничестве и злоупотреблениях . Healthcare Advocates утверждали, что, поскольку они установили файл robots.txt на своем веб-сайте, даже если после подачи первоначального иска Архив должен был удалить все предыдущие копии веб-сайта истца с Wayback Machine, однако некоторые материалы продолжали оставаться быть общедоступным на Wayback. Иск был урегулирован во внесудебном порядке после того, как Wayback устранил проблему.
Сюзанна Шелл
Активист Suzanne Shell подал иск в декабре 2005 года, потребовав Internet Archive платить 100000 $ HER США для архивирования ее сайта profane-justice.org в период между 1999 и 2004 Internet Archive подал декларативное суждение иска в окружном суде Соединенных Штатов для северного округа Калифорнии на 20 января 2006 г., добиваясь судебного определения, что Internet Archive не нарушает авторские права Shell . Shell ответила и подала встречный иск против Internet Archive за архивирование ее сайта, что, как она утверждает, нарушает ее условия обслуживания . 13 февраля 2007 г. судья Окружного суда США округа Колорадо отклонил все встречные иски, за исключением нарушения контракта . Интернет-архив не стал отклонять иски Shell о нарушении авторских прав, связанные с ее копировальной деятельностью, которая также будет продолжена.
25 апреля 2007 г. Internet Archive и Сюзанна Шелл совместно объявили об урегулировании своего иска. Интернет-архив заявил, что «… не заинтересован во включении в Wayback Machine материалов лиц, которые не желают архивировать свой веб-контент. Мы признаем, что у г-жи Шелл есть действующие и подлежащие исполнению авторские права на свой веб-сайт, и мы сожалею, что включение ее веб-сайта в Wayback Machine привело к судебному разбирательству «. Шелл сказал: «Я уважаю историческую ценность цели Internet Archive. Я никогда не намеревался мешать достижению этой цели или причинять ей какой-либо вред».
Даниил Давыдюк
В период с 2013 по 2016 год порнографический актер по имени Даниэль Давыдюк пытался удалить свои заархивированные изображения из архива Wayback Machine, сначала отправив несколько запросов DMCA в архив, а затем обратившись в Федеральный суд Канады .
Ограничения[править | править код]
Исследователи и активисты критикуют Wayback Machine и деятельность Архива Интернета за попытку сохранить все онлайн-материалы, многие из которых не представляют должной ценности. По мнению отдельных исследователей, это связано с устаревшей политикой Архива Интернета, который был основан в конце 1990-х годов — тогда, на заре создания интернет-архивов, считалось, что данные интернета должны сохраняться в полном объёме. Однако с созданием множества однодневных сайтов многие исследователи и активисты поменяли свое мнение. Другие критические замечания относятся к техническим ограничениям сервиса — Wayback Machine не позволяет сохранять и обрабатывать определённые элементы JavaScript, а также может создавать заархивированные страницы, содержащие неработающие ссылки, отсутствующую графику или являющиеся неполными по иным причинам. Сканеры захватывают только статистический снимок сайта — функции порталов на основе Java или Flash работать не будут. Это означает, что бо́льшая часть функциональных возможностей исходной веб-страницы теряется.
Reasons for using the Wayback Downloader
What possible reasons can you have to download sites from the Wayback Machine?
- Missed hosting payments. Let’s say you’re super responsible webmaster. You always update and keep fresh content. You do security updates. You’re on top of things. But one day, you visit your website and all your content is gone! It’s in this moment that you remember that you forgot to change that credit card that was linked to your hosting account. Now all your content is gone! Dashed away by one false move..or is it? Enter our web Archive download bot. With a few simple clicks, you can be on your way to restoring a whole website — exactly like it used to be.
- Nostalgia. Maybe you played a computer game as a teenager or you used to frequently visit some hobby website. Many of these websites change or go offline, but with an archive.org download order, you can recover all your nostalgic memories.Simply go to our wayback machine download site and create your own web.archive.org download. This includes your whole website, up to 10 levels deep, which means all pages that are 10 clicks away from the front page.
- Your site was hacked. What if a more sinister plot involving a hacker compromising the security of your site arises? He’s hijacked your site, and now all your content has been deleted and replaced with ads for his own benefit. Not to worry! We have you covered with a nice Wayback machine download of your website, as it was before disaster struck.
- Legal evidence. Should you ever find yourself embroiled in a legal battle over whatever the issue may be, The Wayback Downloader can help here too. Make a copy of the web archive data for use as evidence in lawsuits. For example, patent law and evidence of prior art. The Wayback Machine accepts removal requests, so it’s a good idea to have your own copy in case the website disappears from the web archive.
- Take content from bankrupt competitor. What if one of your biggest competitors has gone out of business, and with their exit from the business they also took down their website? Remember the URL? Voila! You’ve got yourself a ton of useable information to populate your new site with one less competitor to worry about. Basically, this can be for any site in your industry that was taken offline.
- For recovering expired content. Sometimes you have good expired content — perhaps you found it with our service or with software like the Expired Article Hunter. Let’s say you have a good PBN domain with high metrics, and you have another domain with good expired content. Now you can merge the two domains and rebuilding the expired content on the domain with high metrics. It’s one of the quickest and best methods to build a PBN
- Use it as an alternative to httrack. Httrack is software to scrape live websites, but it doesn’t do a very good job at scraping the internet archive. We rebuild websites as they once were, while httrack simply copies a complete site, including all the headers and archive URLs.
mydrop.io
(реф. ссылка)
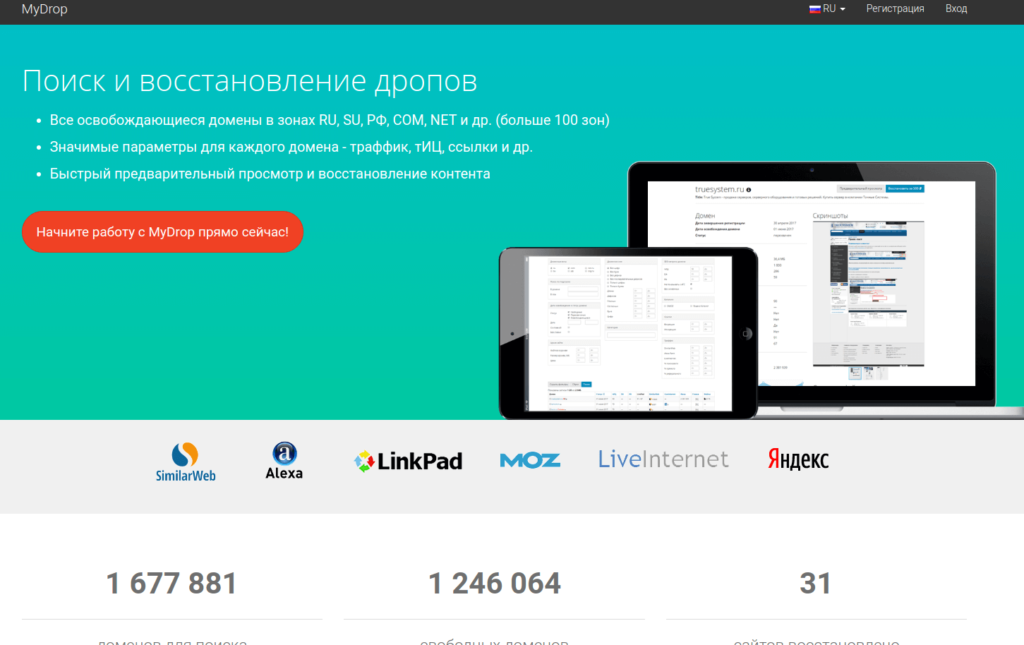
Удобный сервис, кроме фнкционала восстановления контента сайта имеет фунционал поиска доменов по различным параметрам. Пользуюсь им больше года.
Из преимуществ:
- широкий набор фильтров для поиска домена
- возможность подписки на фильтр
- информативная таблица доменов с полезными seo метрикам( TF, CF, DA, PA, LinkPad, SimilarWeb, LiveInternet, Alexa)
- показывают кол-во файлов, которые восстановить и размер в МБ
- показывают, есть ли ставки на домен через сервис expired.ru
- Есть своя Cms
- адекватные цены
- скидки при пополнении счета от 3000 руб.
- интерфейс на русском
Из минусов:
- нет пробного периода либо бесплатного восстановления, если восстонавливаемый сайт «небольшой»
- есть функционал предварительного просмотра, но он очень сыроват и на счета должна быть сумма не меньше чем стоимость восстановления
Page Freezer
Page Freezer is an extremely easy-to-use web and social media archiving service that automatically archives all your website content. This popular alternative to Wayback Machine is used by both webmasters and internet users as webmasters can use it for automatic archiving of web pages and users can find out the archived version of websites that are present on the internet.
The user-friendly interface of Page Freezer makes it very easy for one to see the archived version of the web pages of a website. The only problem with this Internet Wayback Machine alternatives is that you will have to login in order to see the archived web pages or protect your website records.
DomainTools
If you want to find out Whois information or are looking for Wayback Machine alternative then you need to give a try to DomainTools screenshots lookup. As the name of this website suggests, it is going to provide you information about a domain name for free and screenshot history as well.
This website is famous for finding out domain owner and registration information etc. However, you can also find out details such as domain history, how the website looked some time ago using Domain Tools.
The functioning of Domain tools is similar to Screenshots.com as you just have to enter the URL of the website in the search bar and it will list you all the screenshots which are available for that particular website. The database of DomainTools is updated from time to time which makes it a worthy Internet Wayback Machine alternative.
Donation Process
To find out more about what’s involved with physical donations, Rosenberg suggests going to the Help page for details about shipping instructions or dropping off donations smaller than about 20 boxes. All others are asked to complete a physical item donation form to provide all the information to make a larger donation happen, including where the items are located, an accurate count, and other special considerations for the offer.
Part of the donation of 18,000 records from a collector in Washington D.C.
Once submitted, staff begin the planning process to determine if the collection is in a format that can be accepted, if there are duplicates, and the project timeline. Arrangements then can be made for packing and shipping. In the case of larger collections, the Archive typically is able to provide assistance with transportation costs.
Sometimes donors pack their own items and then the Archive pays for the shipping. That was the case for a recent donation of 18,000 records from a music enthusiast in Washington D.C. The donor was looking for a “forever home” for his beloved vinyl and the Archive was happy to schedule a pickup and preserve the rare collection, Rosenberg said.
archive.md
Адреса данного Архива Интернета:
На главной странице говорящие за себя поля:
- Архивировать страницу, которая сейчас онлайн
- Искать сохранённые страницы
Для поиска по сохранённым страницам можно как указывать конкретный URL, так и домены, например:
- microsoft.com покажет снимки с хоста microsoft.com
- *.microsoft.com покажет снимки с хоста microsoft.com и всех его субдоменов (например, www.microsoft.com)
- покажет архив данного url (поиск чувствителен к регистру)
- поиск архивных url начинающихся с http://twitter.com/burg
Данный сервис сохраняет следующие части страницы:
- Текстовое содержимое веб страницы
- Изображения
- Содержимое фреймов
- Контент и изображения загруженные или сгенерированные с помощью Javascript на сайтах Web 2.0
- Скриншоты размером 1024×768 пикселей.
Не сохраняются следующие части веб-страниц:
- Flash и загружаемый им контент
- Видео и звуки
- RSS и другие XML-страницы сохраняются ненадёжно. Большинство из них не сохраняются, или сохраняются как пустые страницы.
Архивируемая страница и все изображения должны быть менее 50 Мегабайт.
Для каждой архивированной страницы создаётся ссылка вида http://archive.is/XXXXX, где XXXXX это уникальный идентификатор страницы. Также к любой сохранённой странице можно получить доступ следующим образом:
- http://archive.is/2013/http://www.google.de/ — самый новый снимок в 2013 году.
- http://archive.is/201301/http://www.google.de/ — самый новый снимок в январе 2013.
- http://archive.is/20130101/http://www.google.de/ — самый новый снимок в течение дня 1 января 2013.
Дату можно продолжить далее, указав часы, минуты и секунды:
- http://archive.is/2013010103/http://www.google.de/
- http://archive.is/201301010313/http://www.google.de/
- http://archive.is/20130101031355/http://www.google.de/
Для улучшения читаемости, год, месяц, день, часы, минуты и секунды могут быть разделены точками, тире или двоеточиями:
- http://archive.is/2013-04-17/http://blog.bo.lt/
- http://archive.is/2013.04.17-12:08:20/http://blog.bo.lt/
Также возможно обратиться ко всем снимкам указанного URL:
http://archive.is/http://www.google.de/
Все сохранённые страницы домена:
http://archive.is/www.google.de
Все сохранённые страницы всех субдоменов
http://archive.is/*.google.de
Чтобы обратиться к самой последней версии страницы в архиве или к самой старой, поддерживаются адреса вида:
- http://archive.is/newest/http://reddit.com/
- http://archive.is/oldest/http://reddit.com/
Чтобы обратиться к определённой части длинной страницы имеется две опции:
В доменах поддерживаются национальные символы:
- http://archive.is/www.maroñas.com.uy
- http://archive.is/*.测试
Обратите внимание, что при создании архивной копии страницы архивируемому сайту отправляется IP адрес человека, создающего снимок страницы. Это делается через заголовок X-Forwarded-For для правильного определения вашего региона и показа соответствующего содержимого.
But What if a Page I want to See is not in the Archive?
Firstly… don’t panic!
It would be a pain a page you wanted to examine was not in the archive. Especially if you wanted to do some of the research I’ve discussed above. The Wayback Machine homepage has a tool that you can use to snapshot a page immediately though. Of course this won’t help to examine a particular issue in the past. But you could at least start archiving the site so it’s available in future.
Type the page URL into the “Save Page Now” box and Wayback Machine will add it to the archive immediately.
The tool will save the page along with any images and CSS it finds there. However, it will not crawl any links it finds on the page and so will not archive the whole domain.
You can add more pages to the archive from a site, but you have to use the “Save Page Now” tool for each one.
If you have concerns about privacy, archive.org does not retain IP addresses on submissions you make to it. So whenever you use the tool your activity is anonymous.
One final note. When a page is archived there is no guarantee when it will be snapshotted again. So you might return to the site again and see only the version that you submitted. Having said this, Wayback Machine will revisit archived pages at some point and the calendar will show this.
Method 2: using FTP
This Tutorial explains how you can recover a website from the Waybackmachine. It also explains exactly how you can upload the files with Cpanel and FTP.
- 1. Download the .zip file with all the HTML files. Extract the files (unzip) to a folder of your choice.
- 2. You need to transfer the files to the server using FTP software. If you don’t have an FTP client already, then we recommend FileZilla: https://filezilla-project.org/
-
3. If you don’t already have an FTP account at your hosting provider, then create one. If your host uses cPanel, then find the icon that says «FTP Accounts» (most hosting providers use cPanel: Hostgator, Godaddy, BlueHost : all of them use cPanel)
cPanel example:It’s usually easier to create an FTP account when adding a domain to your hosting:
- 4. Find the IP address of your server. In GoDaddy you can find your IP address on the hosting dashboard:
-
5. We use FileZilla for Windows in this guide, but you can also download it for Apple computers.
You should now have an FTP account and know your IP address. Open an FTP client. We use FileZilla in this guide.
— Fill in your username and password.
— The username should be
— Host should be the IP address of your server, that will host the Wayback files.
— Port can be blank.
— Press Quickconnect to connect. - 6. Now select all the files and move them to the remote site:
- 7. Your site should work now.
r-tools.org
Первое, что бросается в глаза дизайн сайта стороват. Ребята, пора обновлять!
Плюсы:
- Подходит для парсинга сайтов у которых мало html страниц и много ресурсов другого типа. Потомучто они рассчитывают цену по html страницам
- возможность отказаться от сайта, если качество не устроило. После того как система скачала сайт, вы можете сделать предпросмотр и отказаться если качество не устроило, но только если еще не заказали генерацию архива. (Не проверял эту функцию лично, и не могу сказать на сколько хорошо реализован предпросмотр, но в теории это плюс)
- Внедрена быстрая интеграция сайта с биржей SAPE
- Интерфейс на русском языке
Минусы:
- Есть демо-доступ — это плюс, но я попробовал сделать 4 задания и не получил никакого результата.
- Высокие цены. Парсинг 25000 стр. обойдется в 2475 руб. , а например на Архивариксе 17$. Нужно учесть, что r-tools считает html страницы, архиварикс файлы. Но даже если из всех файлов за 17$ только половина html страницы, все равно у r-tools выходит дороже. (нужно оговориться, что считал при $=70руб. И возможна ситуация, когда r-tools будет выгоден написал про это в плюсах)
Создание[править | править код]
Сервера Архива Интернета, 2008 год
Брюстер Кейл в 2009 году
В 1989 году английский учёный Тим Бернерс-Ли создал всемирную паутину — систему, позволяющую передавать данные через подключённые к интернету компьютеры. Однако с распространением всемирной паутины были выявлены две основные проблемы. Первая состояла в нехватке мест для хранения всех данных, из-за чего многие документы и веб-страницы удалялись. Другая проблема заключалась в том, что после редактирования веб-страницы (например, по юридическим причинам), пользователи не могли посмотреть её изначальную версию. Решить эти недостатки стремилась американская цифровая библиотека «Архив Интернета» — некоммерческая организация, созданная программистами Брюстером Кейлом и Брюсом Галлиатом в 1996 году. При сотрудничестве с Alexa Internet (дочерней компанией Amazon, занимающейся веб-индексированием) Архив инициировал создание и хранение копий существующих сайтов для развития «универсального доступа к знанию». Организация предоставляла бесплатный публичный доступ к оцифрованным материалам, таким как веб-страницы, книги, аудиозаписи, включая живые концерты, видео, изображения и программное обеспечение. На 2021 год штаб-квартира Архива Интернета находится в Сан-Франциско, в здании бывшей христианской церкви, расположенной в районе Ричмонд. Журналист местной радиостанции Kawl в 2019 году сравнивал офис Архива с римским храмом. Организация ставит перед собой цель спасти интернет от исчезновения.
Wayback Machine стал самым известным проектом Архива. Онлайн-сервис был назван в честь машины времени из мультсериала 1960-х годов «Шоу Рокки и Буллвинкля». Он предоставляет доступ к цифровой коллекции из примерно 562 млрд веб-страниц. Проект Wayback Machine был задуман как решение проблемы ошибки 404, означающей, что сервер не может найти данные по запрошенному адресу. Это связано с так называемым вымиранием ссылок — нарастающей недоступностью некогда опубликованных данных. Так, в 1997 году средняя продолжительность жизни веб-страницы составляла 44 дня. В 2003 году этот показатель составил 100 дней. Проведённый в 2008 году анализ ссылок на 2700 цифровых ресурсов, большинство из которых не имеют печатных аналогов, показал, что около 8 процентов ссылок переставали работать через год. К 2011 году, по прошествии трёх лет, 30 процентов ссылок в коллекции были мертвы. Благодаря интеграции с Alexa, столкнувшийся с сообщением об ошибке пользователь мог получить доступ к заархивированной версии страницы через внедрённую в браузер панель инструментов. Если копия недоступной страницы присутствовала в базе данных Wayback Machine, то загоралась специальная кнопка. При этом пользователи могли предоставить браузеру разрешение на просмотр и регистрацию активности — в таком случае все посещаемые сайты архивировались на портале.
Wayback Machine был запущен в мае 1996 года, однако стал доступным для общественности только в 2001-м — до этого вся записанная на цифровых магнитных лентах информация была открыта только для ограниченного числа учёных и исследователей. К моменту «открытия» архив содержал более 10 млрд заархивированных страниц. К декабрю 2014 года руководство Wayback Machine сообщило, что сохранило 435 млрд веб-страниц по всему миру. С технической точки зрения программное обеспечение Wayback Machine не является архивом, а скорее общедоступным интерфейсом к ограниченному подмножеству всех хранилищ. Так, Wayback Machine нельзя считать поисковой системой коллекции организации, так как она не осуществляет поиск по базе данных другой крупной виртуальной библиотеки — Open Library, позволяющей пользователям бесплатно получать доступ к цифровым копиям книг, которые загружаются и архивируются в рамках проекта.