Html кодировки
Содержание:
- Казахский вариант
- Неправильная кодировка HTML страниц
- Немного лирики о том, почему всё так, а не иначе:
- Немного теории
- Кодировка символов в PowerShell Core
- за что отвечает и как работает
- Кодовая страница ANSI
- Кодировка символов в Windows PowerShell
- Неправильная кодировка результатов из базы данных MySQL
- Как исправить иероглифы Windows 10 путем изменения кодовых страниц
- Немного из истории
- Кодировка в .htaccess
- Настройте буферы командной строки с историческими записями
- Как сменить кодировку текстового файла с помощью Блокнота в Windows
Казахский вариант
Измененная версия Windows-1251 была стандартизирована в Казахстане как казахстанский стандарт STRK1048 и известна под этикеткой . Он отличается в строках, показанных ниже:
| _0 | _1 | _2 | _3 | _4 | _5 | _6 | _7 | _8 | _9 | _A | _B | _C | _D | _E | _F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 8_ 128 | Ђ 0402 | Ѓ 0403 | ‚ 201A | ѓ 0453 | „ 201E | … 2026 г. | † 2020 г. | ‡ 2021 г. | € 20AC | ‰ 2030 г. | Љ 0409 | ‹ 2039 | Њ 040A | Қ 049A | Һ 04BA | Џ 040F |
| 9_ 144 | ђ 0452 | ‘ 2018 | ‘ 2019 | 201C | ” 201D | • 2022 г. | — 2013 г. | — 2014 г. | 2122 | љ 0459 | › 203A | њ 045A | қ 049B | һ 04BB | џ 045F | |
| A_ 160 | NBSP 00A0 | Ұ 04B0 | ұ 04B1 | Ә 04D8 | ¤ 00A4 | Ө 04E8 | ¦ 00A6 | § 00A7 | Ё 0401 | 00A9 | Ғ 0492 | 00AB | ¬ 00AC | SHY 00AD | 00AE | Ү 04AE |
| B_ 176 | ° 00B0 | ± 00B1 | І 0406 | і 0456 | ө 04E9 | µ 00B5 | ¶ 00B6 | · 00B7 | ё 0451 | № 2116 | ғ 0493 | 00BB | ә 04D9 | Ң 04A2 | ң 04A3 | ү 04AF |
Неправильная кодировка HTML страниц
Создадим тестовый файлик:
sudo gedit /var/www/html/encoding.html
Скопируем в него следующий HTML код, в котором отсутствует указание кодировки и посмотрим, какие проблемы могут с ним возникнуть и как их решить:
<html>
<head>
<title>Проверка кодировки</title>
</head>
<body>
<h1>Тестовый файл для проверки кодировки</h1>
</body>
</html>
Откроем этот файл в браузере http://localhost/encoding.html
Как можно видеть, кодировка браузером определена неправильно:

Имеется несколько способов исправить эту ситуацию. Начнём с самого простого – явно указать кодировку для веб-страницы. Это делается метатегом, который должен быть расположен внутри тэга head:
<meta http-equiv="content-type" content="text/html; charset=utf-8" />
Добавим эту строку к нашему тестовому файлику, чтобы получилось так:
<html>
<head>
<title>Проверка кодировки</title>
<meta http-equiv="content-type" content="text/html; charset=utf-8" />
</head>
<body>
<h1>Тестовый файл для проверки кодировки</h1>
</body>
</html>
Как мы можем убедиться на следующем скриншоте, проблема решена:

Если кодировка вашего файла отличается от UTF-8, то вместо неё поставьте windows-1251 или ту, которая соответствует кодировке веб-страницы. Чтобы научиться определять кодировку файлов, посмотрите эту инструкцию.
Это был самый простой способ исправления проблемы с кодировкой – без изменения настроек сервера.
Вернём наш тестовый файл в исходное состояние и продолжим изучение способов указания кодировки.
Если файлы .htaccess включены настройками Apache, то эти файлы можно использовать чтобы указывать кодировку отправляемых веб-сервером страниц. Чтобы включить поддержку файлов .htaccess в конфигурационном файле Apache ( /etc/apache2/apache2.conf ) найдите группу строк
<Directory /var/www/> Options Indexes FollowSymLinks AllowOverride None Require all granted </Directory>
И в ней замените
AllowOverride None
на
AllowOverride All
После этого сервер нужно перезапустить.
sudo systemctl restart apache2.service
Файл .htaccess должен быть размещён в той же директории, что и сайт. Мой сайт размещён в корневой директории веб-сервера. Если у вас также, то теперь в папке /var/www/html/ создайте файл .htaccess и добавьте в него директиву AddDefaultCharset после которой укажите желаемую кодировку. Примеры
AddDefaultCharset UTF-8
ИЛИ
AddDefaultCharset windows-1251
Можно указать кодировку, которая будет применена только к файлам определённого формата:
AddCharset utf-8 .atom .css .js .json .rss .vtt .xml
Набор файлов может быть любым, например:
AddCharset utf-8 .html .css .php .txt .js
Следующий вариант является альтернативным и также позволяет устанавливать кодировку для файлов определённого типа, для него нужно, чтобы был включён mod_headers:
<Files ~ "\.html?$">
Header set Content-Type "text/html; charset=utf-8"
</Files>
Ещё один вариант, который также можно использовать в файле .htaccess для установки кодировки UTF-8:
IndexOptions +Charset=utf-8
Если сайт на PHP, то дополнительно может понадобиться продублировать кодировку с php_value default_charset:
AddDefaultCharset windows-1251 php_value default_charset "cp1251"
Можно вместо создания файла .htaccess установить кодировку в конфигурационном файле веб-сервера. Для Apache CentOS/Fedora это файл httpd.conf, а на Debian/Ubuntu это файл apache2.conf. Добавьте следующую строку для установки кодировки и перезапустите веб-сервер, чтобы изменения вступили в силу:
AddDefaultCharset UTF-8
Немного лирики о том, почему всё так, а не иначе:
Но и для пользователей, остающихся обычными «пользователями ПК» проблема с кодировками кириллистических символов иногда встаёт довольно остро. «Кракозяблики» — наследие предыдущей эпохи, когда каждый программист писал собственную таблицу кодировок. Например, скачал и хочешь почитать интересную книжку, а тут такое >=O
И так продолжалось до тех пор, пока не начали вводиться стандарты. Но и стандартов на текущее время уже немало. Например, есть кодировка Unicode, есть UTF-8, есть UTF-16 и так далее.
Я так и не нашёл, как сменить кодировку по умолчанию при открытии Блокнота и создания нового документа уже из открытой сессии Блокнота.
Зато нашёл, как сменить кодировку по умолчанию, когда текстовый документ сначала создаётся (из контекстного меню) и только потому открывается Блокнотом. Тогда кодировка файла будет та, которая будет прописана по умолчанию. Об этом и пойдёт ниже речь.
Итак, для того, чтобы поменять кодировку создаваемых текстовых документов по умолчанию, нам понадобиться внести изменения в Реестр Windows.
Ну и хватит лирики. К делу!
Немного теории
Любой документ на компьютере или в интернете, как я уже сказал, хранится в виде двоичного кода. К примеру, если вы используете кодировку ASCII, то буква «К» будет записана как 10001010, а windows 1251 под этим числом скрывается символ – Љ. В итоге, если браузер или программа обратится к другой таблице и считает вместо ASCII коды windows 1251, то читатель увидит совершенно непонятные ему символ.
Логичен вопрос, нафига было придумывать множество таблиц с кодами? Дело в том, что помимо русского алфавита существует еще и английский, немецкий, китайский. По некоторым подсчетам, существует около 200 000 символов. Хотя, я не очень доверяю этой статистике, вспоминая про японский.
Не забывайте, что для заглавной и строчной буквы нужно придумать свой код, есть запятые, тире и так далее.
Чем больше в таблице символов, тем длиннее код каждого из них, а значит и вес документа становится больше.
Представьте, если бы одна книга весила 4 Гб! Она бы очень долго загружалась, занимала все свободное место на компьютере. Решение о скачивании представлялось бы делом нелегким.
Если вспомнить о сайтах, то вообще страшно подумать, что бы произошло. Каждая страничка открывалась даже на скоростном оптоволокне по часу с лишним! Думаю, мобильные телефоны можно было бы смело выкидывать. Пользоваться ими на улице даже с 4G? Сомневаюсь.
По этим причинам каждый программист в свое время старался придумать свою таблицу символов. Чтобы было удобно для использования и вес сохранялся оптимальным.
Microsoft, к примеру, для русскоязычного сегмента создали windows-1251. В ней, конечно же, есть свои достоинства и недостатки. Как и у любого другого продукта.
Сейчас уже, лишь 2% всех страниц в интернете написано на 1251. Большинство веб-мастеров используют UTF-8. Почему так?
Кодировка символов в PowerShell Core
В PowerShell Core (V6 и более поздних версий) параметр Encoding поддерживает следующие значения:
- : Использует кодировку для набора символов ASCII (7-разрядных).
- : Кодируется в формате UTF-16 с обратным порядком байтов.
- : Использует кодировку по умолчанию для программ MS-DOS и консолей.
- : Кодируется в формате UTF-16 с прямым порядком байтов.
- : Кодируется в формате UTF-7.
- : Кодирует в формате UTF-8 (без спецификации).
- : Кодирует в формате UTF-8 с меткой порядка байтов (BOM)
- : Кодирует в формате UTF-8 без метки порядка байтов (BOM)
- : Кодируется в формате UTF-32.
По умолчанию PowerShell Core имеет значение для всех выходных данных.
Начиная с PowerShell 6,2, параметр кодировки также разрешает числовые идентификаторы зарегистрированных кодовых страниц (например ,) или строковых имен зарегистрированных кодовых страниц (например ,). Дополнительные сведения см. в документации .NET по кодированию. codepage.
за что отвечает и как работает
В начале 90-х, когда произошел развал СССР и границы России были открыты, к нам стали поступать программные продукты западного производства. Естественно, все они были англоязычными. В это же время начинает развиваться Интернет. Остро встала проблема русификации ресурсов и программ. Тогда и была придумана русская кодировка Windows 1251. Она позволяет корректно отображать буквы славянских алфавитов:
- русского;
- украинского;
- белорусского;
- сербского;
- болгарского;
- македонского.
Разработка велась русским представительством Microsoft совместно с компаниями «Диалог» и «Параграф». За основу были взяты самописные разработки, которые в 1990-91гг имели хождение среди немногочисленных идеологов ИТ в России.
На сегодняшний день разработан более универсальный способ кодировать символы — UTF-8 (Юникод). В нем представлено почти 90% всех программных и веб-ресурсов. Windows 1251 применяется в 1,6% случаев. (Информация по исследованиям Web Technology Surveys)
Кодировка сайта utf 8 или Windows 1251?
Чтобы ответить на этот вопрос, необходимо немного понять, что такое кодировка и чем они отличаются. Текстовая информация, как впрочем, и любая другая, в компьютере хранится в закодированном виде. Нам легче представить ее как числа. Каждый символ может занимать один или более байт. Windows 1251 является однобайтной кодировкой, а UTF-8 восьмибайтной. Это значит, что в Windows 1251 можно закодировать всего 256 символов.Так как все сводится к двоичной системе исчисления, а байт – это 8 бит (0 и 1), то и максимальное число сочетаний составляет 28 = 256. Юникод позволяет представлять куда большее число символов, да и на каждый может быть выделен больший размер.
Отсюда и следуют преимущества Юникода:
- В шапке сайта следует указать кодировку, которая используется. Иначе вместо символов отобразятся «кракозяблы». А Юникод является стандартным для всех браузеров – они ловят его «на лету» как установленный по умолчанию.
- Символы сайта останутся одними и теми же, независимо от того, в какой стране загружается ресурс. Это зависит не от географического расположения серверов, а от языка программного обеспечения рабочих станций клиента. Житель Португалии, очевидно, использует клавиатуру и все ПО, включая операционную систему, на родном языке. В его компьютере, скорее всего вообще отсутствует Windows 1251. А если это так, то и сайты на русском языке корректно открываться не будут. Юникод, в свою очередь, «зашит» в любую ОС на любом языке.
- UTF-8 позволяет закодировать большее количество символов. На данный момент используется 6 байт из 8-ми, а русские символы кодируются двумя байтами.Именно поэтому предпочтительней использовать универсальную кодировку, а не узкоспециализированную, которая применяется только в славянских странах.
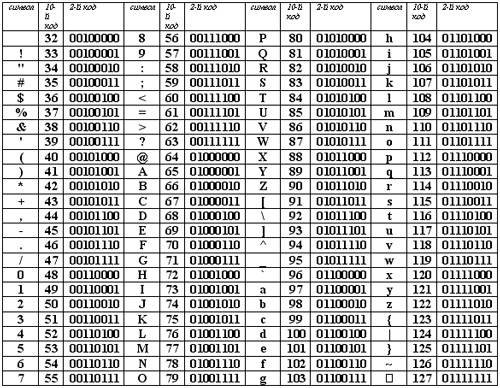
Таблица кодировки Windows 1251
Для программистов и разработчиков сайтов бывает необходимо знать номера символов. Для этого используются специальные таблицы кодировки. Ниже представлена таблица для Windows 1251.
Что делать, если слетела кодировка командной строки?
Иногда Вы можете столкнуться с ситуацией, когда в командной строке вместо русских отображаются непонятные символы. Это означает, что возникла проблема кодировки командной строки Windows 7. Почему 7-ка? Потому что, начиная с 8-й версии, используется UTF-8, а в семерке еще Windows 1251.Единовременно помочь решить проблему может команда chcp 866. Текущий сеанс будет работать корректно. А вот чтобы исправить ошибку кардинально, понадобится реестр.
- Нажмите Win+R и наберите команду regedit. Это позволит попасть в редактор реестра.
- Перейдите по ветке HKEY_CURRENT_USER\Console и посмотрите, чему равно значение для CodePage. Скорее всего, вы увидите что-то, отличное от 866 (правильный вариант).
- Исправьте на 866 в положении «Десятичная».
- Закройте и откройте вновь командную строку. Ситуация должна исправиться.
Кодовая страница ANSI
| Псевдоним (а) | ANSI (неверное название) |
|---|---|
| Стандарт | Стандарт кодирования WHATWG |
| Расширяется | US-ASCII |
| Предшествует | ISO 8859 |
| Преемник | Юникод UTF-16 (в Win32 API) |
Кодовые страницы ANSI (официально называемые «кодовыми страницами Windows» после того, как Microsoft приняла неправильное употребление первого термина) используются для приложений, не поддерживающих Unicode (скажем, ориентированных на байты ), использующих графический пользовательский интерфейс в системах Windows. Термин «ANSI» является неправильным, потому что эти кодовые страницы Windows не соответствуют ни одному стандарту ANSI; Кодовая страница 1252 была основана на раннем проекте ANSI, который стал международным стандартом ISO 8859-1 , который добавляет еще 32 управляющих кода и пространство для 96 печатаемых символов. Среди других отличий кодовые страницы Windows выделяют печатаемые символы в дополнительное пространство управляющего кода, что делает их в лучшем случае неразборчивыми для совместимых со стандартами операционных систем.)
Большинство устаревших кодовых страниц «ANSI» имеют номера кодовых страниц в шаблоне 125x. Тем не менее, (тайский) и восточноазиатские многобайтовые кодовые страницы ANSI ( , , , ), все из которых также используются в качестве кодовых страниц OEM, пронумерованы для соответствия аналогичным (но не идентичным) кодовым страницам IBM. кодировки. Хотя кодовая страница 1258 также используется как кодовая страница OEM, она является оригинальной для Microsoft, а не расширением существующей кодировки. IBM присвоила свои собственные, разные номера вариантам Microsoft, они приведены для справки в приведенных ниже списках, где это применимо.
Все кодовые страницы Windows 125x, а также 874 и 936, помечены Internet Assigned Numbers Authority (IANA) как « номер Windows», хотя «Windows-936» рассматривается как синоним « GBK ». Кодовая страница Windows 932 вместо этого помечена как «Windows-31J».
Кодовые страницы ANSI Windows, и особенно кодовая страница , были так названы, поскольку они якобы были основаны на черновиках, представленных или предназначенных для ANSI. Однако ANSI и ISO не стандартизировали ни одну из этих кодовых страниц. Вместо этого они либо:
- Надмножества стандартных наборов, таких как ISO 8859 и различных национальных стандартов (например, Windows-1252 и ISO-8859-1 ),
- Основные их модификации (делающие их несовместимыми в разной степени, например, Windows-1250 и ISO-8859-2 )
- Отсутствие параллельного кодирования (например, Windows-1257 против ISO-8859-4 ; ISO-8859-13 был введен намного позже). Кроме того, Windows-1251 не следует ни ISO-стандартизированному ISO-8859-5, ни преобладающему в то время KOI-8 .
Microsoft присвоила около двенадцати типографских и деловых символов (включая, в частности, знак евро , €) в CP1252 кодовые точки 0x80–0x9F, которые в ISO 8859 присвоены управляющим кодам C1 . Эти назначения также присутствуют во многих других кодовых страницах ANSI / Windows в тех же кодовых точках. Windows не использовала управляющие коды C1, поэтому это решение не имело прямого влияния на пользователей Windows. Однако при включении в файл, передаваемый на совместимую со стандартами платформу, такую как Unix или MacOS, информация была невидимой и потенциально опасной.
Кодировка символов в Windows PowerShell
В PowerShell 5,1 параметр Encoding поддерживает следующие значения:
- Использует кодировку ASCII (7-разрядных).
- Использует UTF-16 с обратным порядком байтов.
- Использует UTF-32 с обратным порядком байтов.
- Кодирует набор символов в последовательность байтов.
- Использует кодировку, соответствующую активной кодовой странице системы (обычно ANSI).
- Использует кодировку, соответствующую текущей кодовой странице OEM системы.
- аналогичен .
- Использует UTF-16 с прямым порядком байтов.
- аналогичен .
- Использует UTF-32 с прямым порядком байтов.
- Использует UTF-7.
- Использует UTF-8 (с BOM).
в общем случае Windows PowerShell по умолчанию использует кодировку юникод UTF-16le . однако кодировка по умолчанию, используемая командлетами в Windows PowerShell, не согласуется.
Примечание
При использовании любой кодировки Юникода, за исключением , всегда создает спецификацию.
Для командлетов, записывающих выходные данные в файлы:
-
и операторы перенаправления и создают UTF-16LE, который, в свою очередь, отличается от и .
-
а также создавать файлы UTF-16LE.
-
Если целевой файл пуст или не существует, и Используйте кодировку. — это кодировка, определяемая кодовой страницей устаревшей версии ANSI на языке активного системы.
-
создает файлы, но использует другую кодировку при использовании параметра append (см. ниже).
-
по умолчанию создает файлы UTF-8 с BOM.
-
создает файл UTF-8 с кодировкой BOM.
-
по умолчанию использует кодировку.
-
создает файлы с помощью спецификации. При использовании параметра append кодировка может отличаться (см. ниже).
Для команд, которые добавляют к существующему файлу:
-
и оператор перенаправления не пытается сопоставить кодировку содержимого существующего целевого файла. Вместо этого они используют кодировку по умолчанию, если не используется параметр Encoding . При добавлении содержимого необходимо использовать исходную кодировку файлов.
-
При отсутствии явного параметра кодировки обнаруживает существующую кодировку и автоматически применяет ее к новому содержимому. Если имеющееся содержимое не имеет BOM, используется кодировка ANSI. Поведение аналогично в PowerShell Core (V6 и более поздних версиях), кроме кодировки по умолчанию — .
-
соответствует существующей кодировке, если целевой файл содержит СПЕЦИФИКАЦИю. В отсутствие спецификации используется Кодировка.
-
соответствует существующей кодировке файлов, включающих СПЕЦИФИКАЦИю. При отсутствии спецификации по умолчанию используется Кодировка. Такая кодировка может привести к утере данных или повреждению символов, если данные в записи содержат многобайтовые символы.
Для командлетов, считывающих строковые данные в отсутствие спецификации:
-
и использует кодировку ANSI. ANSI также используется механизмом PowerShell при чтении исходного кода из файлов.
-
, и предполагают отсутствие спецификации.
Неправильная кодировка результатов из базы данных MySQL
Если ваш сайт состоит из статической части (шаблон) и динамической, которая формируется из данных, получаемых из базы данных, то может возникнуть ситуация, когда часть сайта имеет правильную кодировку, а другая часть сайта имеет неправильную. В этом случае бесполезно менять настройки веб-сервера – поскольку всё равно часть страницы будет иметь неправильную кодировку.
Нужно начать с определения кодировки ваших таблиц. Можно посмотреть в phpMyAdmin:
Обратите внимание на столбец «Сравнение», запись «utf8_unicode_ci» означает, что используется кодировка UTF-8. Можно подключиться к СУБД MySQL и проверить кодировку таблиц без phpMyAdmin
Для этого:
Можно подключиться к СУБД MySQL и проверить кодировку таблиц без phpMyAdmin. Для этого:
mysql -u root -p
Если вы забыли имя базы данных, то выполните команду:
SHOW DATABASES;
Предположим, я хочу посмотреть кодировку для таблиц в базе данных information_schema
USE information_schema;
Если вы забыли имя таблиц, выполните:
SHOW TABLES;
Далее выполните команду, в которой имя_таблицы замените на настоящее имя таблицы:
SHOW FULL COLUMNS FROM имя_таблицы;
Например:
SHOW FULL COLUMNS FROM GLOBAL_STATUS;
Вы увидите примерно следующее:
Смотрите столбец Collation. В моём случае там utf8_general_ci, это, как и utf8_unicode_ci, кодировка UTF-8. Кстати, если вы не знаете в чём разница между кодировками utf8_general_ci, utf8_unicode_ci, utf8mb4_general_ci, utf8mb4_unicode_ci, а также какую кодировку выбрать для базы данных MySQL, то посмотрите эту статью.
Теперь, когда мы узнали кодировку (в моём случае это UTF-8), то при каждом подключении к СУБД MySQL нужно выполнять последовательно запросы:
SET NAMES UTF8 SET CHARACTER SET UTF8 SET character_set_client = UTF8 SET character_set_connection = UTF8 SET character_set_results = UTF8
В PHP это можно сделать примерно так:
$this->mysqli = new mysqli($server, $username, $password, $basename); if ($this->mysqli->connect_error) { $this->errorHandler_c->logError(1, ‘Connect Error (‘ . $this->mysqli->connect_errno . ‘) ‘ . $this->mysqli->connect_error, $_SERVER ); } $this->mysqli->query(«SET NAMES UTF8»); $this->mysqli->query(«SET CHARACTER SET UTF8»); $this->mysqli->query(«SET character_set_client = UTF8»); $this->mysqli->query(«SET character_set_connection = UTF8»); $this->mysqli->query(«SET character_set_results = UTF8»);
Обратите внимание, что UTF8 вам нужно заменить на ту кодировку, которая используется для ваших таблиц
Как исправить иероглифы Windows 10 путем изменения кодовых страниц
Кодовые страницы представляют собой таблицы, в которых определенным байтам сопоставляются определенные символы, а отображение кириллицы в виде иероглифов в Windows 10 связано обычно с тем, что по умолчанию задана не та кодовая страница и это можно исправить несколькими способами, которые могут быть полезны, когда требуется не изменять язык системы в параметрах.
С помощью редактора реестра
Первый способ — использовать редактор реестра. На мой взгляд, это самый щадящий для системы метод, тем не менее, рекомендую создать точку восстановления прежде чем начинать. Совет про точки восстановления относится и ко всем последующим способам в этом руководстве.
Обычно, это исправляет проблему с отображением русских букв. Вариация способа с помощью редактора реестра (но менее предпочтительная) — посмотреть на текущее значение параметра ACP (обычно — 1252 для изначально англоязычных систем), затем в том же разделе реестра найти параметр с именем 1252 и изменить его значение с c_1252.nls на c_1251.nls.
Путем подмена файла кодовой страницы на c_1251.nls
Второй, не рекомендуемый мной способ, но иногда выбираемый теми, кто считает, что правка реестра — это слишком сложно или опасно: подмена файла кодовой страницы в C:\ Windows\ System32 (предполагается, что у вас установлена западно-европейская кодовая страница — 1252, обычно это так. Посмотреть текущую кодовую страницу можно в параметре ACP в реестре, как было описано в предыдущем способе).
После перезагрузки Windows 10 кириллица должна будет отображаться не в виде иероглифов, а как обычные русские буквы.
Немного из истории
С наступлением 90-х годов, после распада СССР, границы России стали открыты.
Поэтому на территорию страны стало постепенно проникать оборудование из европейских стран.
Изначально все они были запрограммированы на английском языке.
В этот же промежуток времени начинает активно распространяться интернет.
В результате стало необходимо как можно быстрее русифицировать все оборудование и программное обеспечение. В связи с данной необходимостью появилась кодировка 1251. С ее помощью на компьютерах корректно отображаются славянские буквы алфавита.
А значит стало возможным использовать компьютеры со следующими языками:
- Русский
- Белорусский
- Украинский
- Сербский
- Болгарский
- Македонский.
Совместно с двумя российскими и «Диалог», представительства ] Microsoft начали активно заниматься разработкой данной кодировки.
В качестве основы были использованы обыкновенные самостоятельно написанные разработки.

Однако технический прогресс не стоит на месте, поэтому в последнее время широкое применение нашел Юникод UTF-8.
В него заложено порядком 90% web-ресурсов. Что касается 1251, то она используется менее, чем в 2%.
Кодировка в .htaccess
Пункт третий
Если при открытии данного документа в браузере перед вами все равно появляются некорректные символы, здесь уже причина в настройках сервера. Тем не менее, решить эту проблему также не сложно. Для этого вам понадобится лишь одна строчка в файле .htaccess. Данный файл находится в корневой директории Вашего сайта, вместе с индексным файлом. Если файл .htaccess отсутствует в корневой директории, то его следует создать. В этом файле нужно прописать следующую строку:
AddDefaultCharset UTF-8
Разумеется, если вы используете Windows-1251, то вместо UTF-8 следует прописать WINDOWS-1251. Затем файл .htaccess нужно сохранить. Перезапускать сервер после этого не обязательно.
Настройте буферы командной строки с историческими записями
Буфер служит исторической записью команд, которые вы выполнили, и вы можете перемещаться по командам, которые вы ранее ввели в командной строке, с помощью клавиш со стрелками вверх и вниз. Вы можете изменить настройки приложения для буферов в разделе «История команд» на вкладке «Параметры».
Настройте, сколько команд сохраняется в буфере команд, установив размер буфера. Хотя по умолчанию установлено 50 команд, вы можете установить его равным 999, но имейте в виду, что это занимает ОЗУ. Проверка опции «Discard Old Duplicates» в нижней части раздела позволяет Windows 10 удалять дубликаты записей команд из буфера.
Вторая опция, «Количество буферов», определяет максимальное количество одновременных экземпляров, чтобы иметь свои собственные буферы команд. Значение по умолчанию — 4, поэтому вы можете открыть до четырех экземпляров командной строки, каждый со своим отдельным буфером. После этого ограничения ваши буферы перерабатываются для других процессов.
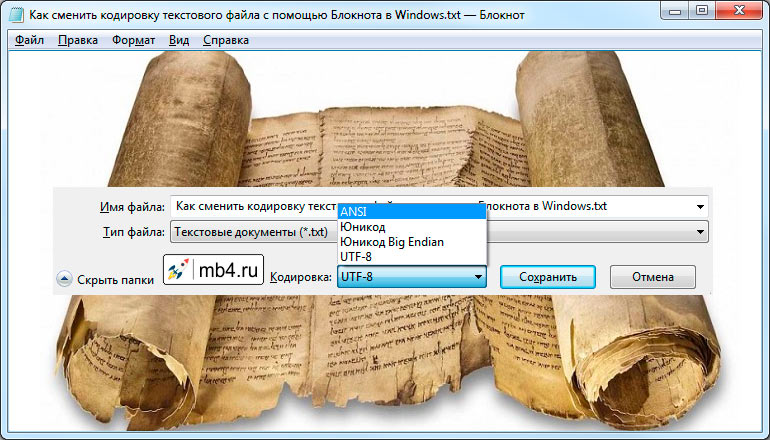
Как сменить кодировку текстового файла с помощью Блокнота в Windows
Фишка кодировки текстовых фалов в том, что хранятся не сами буквы (символы), а ссылки на них в таблице кодировок. Если с латинским буквами, арабскими цифрами и основными символами типа точек, тире и запятых никаких проблем не возникает: во многих таблицах кодировок все эти буквы, цифры и символы находятся в одних и тех же ячейках, то с кириллицей всё сложно. Например, в разных кодировках буква Ы может находиться в ячейке 211, 114 и 69.
Именно поэтому на заре интернета чтобы посмотреть разные сайты с разными кодировками приходилось подбирать кодировку. (Но кто это помнит?) Сейчас кодировка страницы обычно прописана в заголовке страницы, что позволяет браузеру “автоматически” подбирать отображение символов на наших мониторах.
Надеюсь, что мотивация для обращение необходимого внимания на кодировку достаточная и можно перейти к сути вопроса: “Как же, чёрт возьми, сохранить файл в нужной кодировке?!”
В этой статье речь пойдёт как раз о том, как сохранить текстовый файл с помощью программы Блокнот (Notepad) в Windows в нужной кодировке.
Для того, чтобы изменить кодировку текстового файла, конечно же сперва его нужно создать. А после того, как файл создан, нужно ещё суметь его открыть. Самый простой способ отрыть файл — это двойной клик левой кнопкой мыши по его иконке в проводнике:

Чтобы поменять кодировку в открывшемся файле, нужно в меню «Файл» текстового редактора Блокнот выбрать пункт «Сохранить как. »:
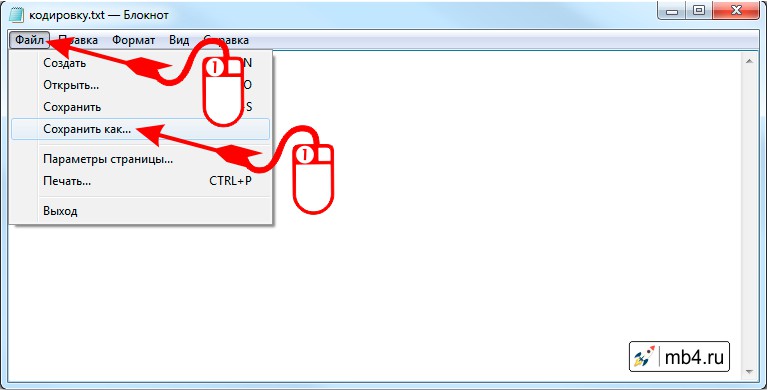
Откроется диалоговое окно сохранения файла. Для смены кодировки, нужно выбрать из списка предлагаемых необходимый:
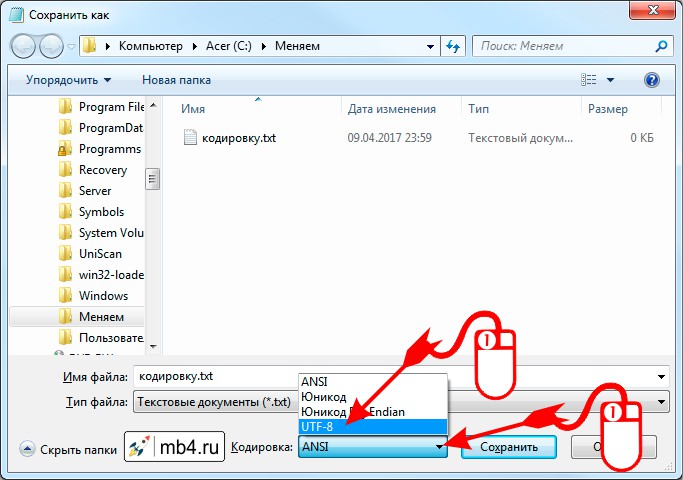
После того, как нужная кодировка выбрана, можно кликнуть на кнопку «Сохранить» или просто нажать Enter:
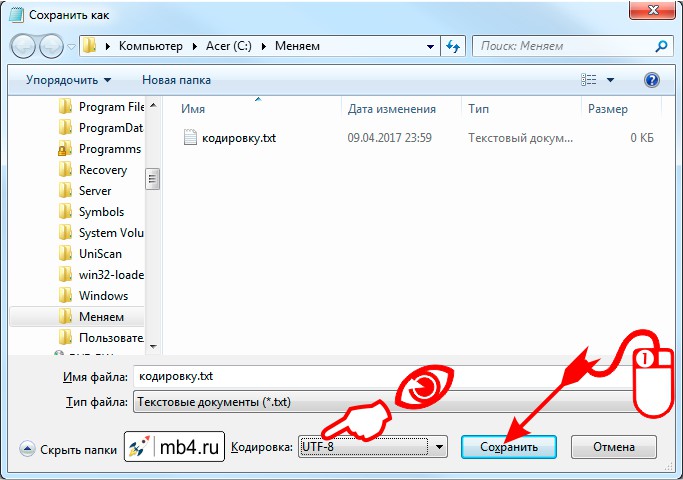
Так как мы не изменили имя файла, то будет перезаписан тот же самый файл. Поэтому возникает справедливый вопрос: «Файл с таким именем уже существует. Заменить?» Ну да, мы к этому и стремимся! Поменять кодировку у этого файла. Поэтому его нужно перезаписать с новой кодировкой. Соглашаемся:
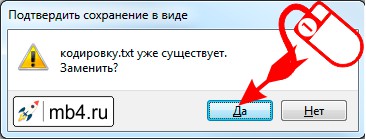
Всё! Миссия по смене кодировки в текстовом файле выполнена! Файл сохранён с новой кодировкой. Можно закрыть текстовый редактор и устроить празднование этого решающего события! =D