Корреляционный анализ в excel
Содержание:
- Функция КОРРЕЛ для определения взаимосвязи и корреляции в Excel
- Выборочный r и популяционный ρ
- Что такое корреляция простыми словами
- Разбор результатов анализа
- Суть корреляционного анализа
- Корреляция и диверсификация
- Пример применения метода корреляционного анализа
- Что такое коэффициент корреляции?
- Коэффициент парной корреляции в Excel
- Как проводится корреляционный анализ в Excel
- Как вы можете рассчитать корреляцию с помощью Excel? — 2019
- Как рассчитать коэффициент корреляции в Excel
Функция КОРРЕЛ для определения взаимосвязи и корреляции в Excel
КОРРЕЛ – функция, применяемая для подсчета коэффициента корреляции между 2-мя массивами. Разберем на четырех примерах все способности этой функции.
Примеры использования функции КОРРЕЛ в Excel
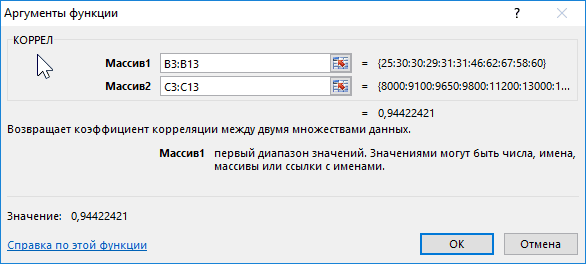
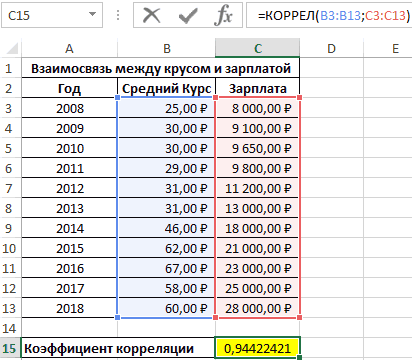
Первый пример. Есть табличка, в которой расписана информация об усредненных показателях заработной платы работников компании на протяжении одиннадцати лет и курсе $. Необходимо выявить связь между этими 2-умя величинами. Табличка выглядит следующим образом:
24
Алгоритм расчёта выглядит следующим образом:
 25
25
Отображенный показатель близок к 1. Результат:
 26
26
Определение коэффициента корреляции влияния действий на результат
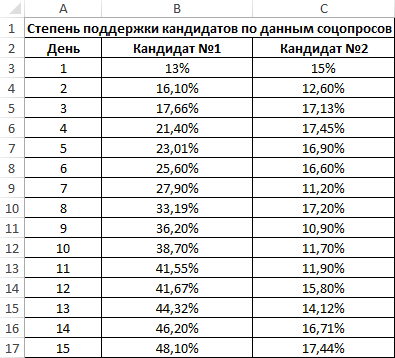
Второй пример. Два претендента обратились за помощью к двум разным агентствам для реализации рекламного продвижения длительностью в пятнадцать суток. Каждые сутки проводился социальный опрос, определяющий степень поддержки каждого претендента. Любой опрошенный мог выбрать одного из двух претендентов или же выступить против всех. Необходимо определить, как сильно повлияло каждое рекламное продвижение на степень поддержки претендентов, какая компания эффективней.
 27
27
Используя нижеприведенные формулы, рассчитаем коэффициент корреляции:
- =КОРРЕЛ(А3:А17;В3:В17).
- =КОРРЕЛ(А3:А17;С3:С17).
Результаты:
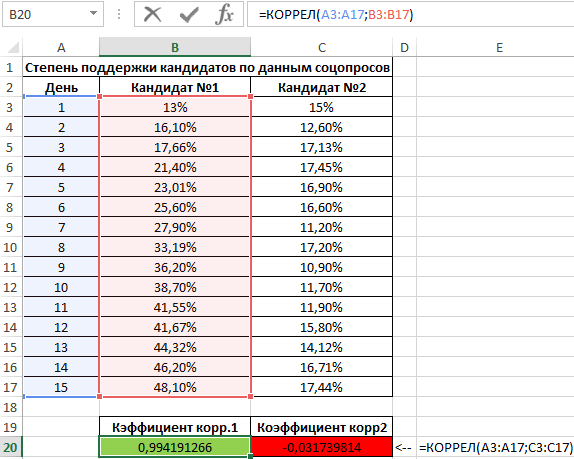 28
28
Из полученных результатов становится понятно, что степень поддержки 1-го претендента повышалась с каждыми сутками проведения рекламного продвижения, следовательно, коэффициент корреляции приближается к 1. При запуске рекламы другой претендент обладал большим числом доверия, и на протяжении 5 дней была положительная динамика. Потом степень доверия понизилась и к пятнадцатым суткам опустилась ниже изначальных показателей. Низкие показатели говорят о том, что рекламное продвижение отрицательно повлияло на поддержку. Не стоит забывать, что на показатели могли повлиять и остальные сопутствующие факторы, не рассматриваемые в табличной форме.
Анализ популярности контента по корреляции просмотров и репостов видео
Третий пример. Человек для продвижения собственных роликов на видеохостинге Ютуб применяет соцсети для рекламирования канала. Он замечает, что существует некая взаимосвязь между числом репостов в соцсетях и количеством просмотров на канале. Можно ли про помощи инструментов табличного процессора произвести прогноз будущих показателей? Необходимо выявить резонность применения уравнения линейной регрессии для прогнозирования числа просмотров видеозаписей в зависимости от количества репостов. Табличка со значениями:
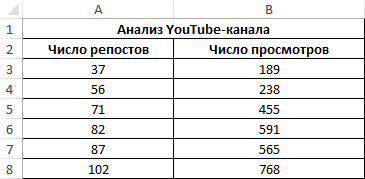 29
29
Теперь необходимо провести определение наличия связи между 2-мя показателями по нижеприведенной формуле:
0,7;ЕСЛИ(КОРРЕЛ(A3:A8;B3:B8)>0,7;”Сильная прямая зависимость”;”Сильная обратная зависимость”);”Слабая зависимость или ее отсутствие”)’ class=’formula’>
Если полученный коэффициент выше 0,7, то целесообразней применять функцию линейной регрессии. В рассматриваемом примере делаем:
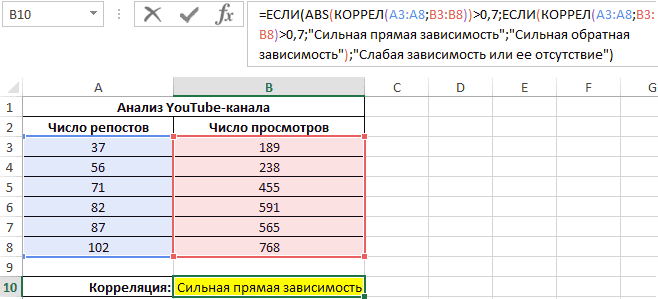 30
30
Теперь производим построение графика:
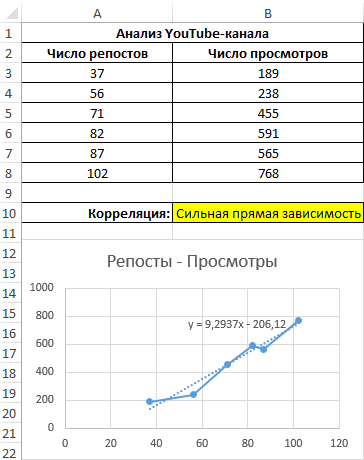 31
31
Применяем это уравнение, чтобы определить число просматриваний при 200, 500 и 1000 репостов: =9,2937*D4-206,12. Получаем следующие результаты:
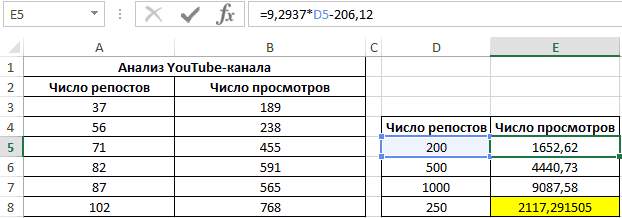 32
32
Функция ПРЕДСКАЗ позволяет определить число просмотров в моменте, если было проведено, к примеру, двести пятьдесят репостов. Применяем: 0,7;ПРЕДСКАЗ(D7;B3:B8;A3:A8);”Величины не взаимосвязаны”)’ class=’formula’>. Получаем следующие результаты:
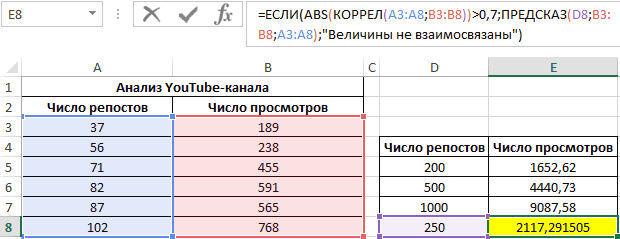 33
33
Особенности использования функции КОРРЕЛ в Excel
Данная функция имеет нижеприведенные особенности:
- Не учитываются ячейки пустого типа.
- Не учитываются ячейки, в которых находится информация типа Boolean и Text.
- Двойное отрицание «–» применяется для учёта логических величин в виде чисел.
- Количество ячеек в исследуемых массивах обязаны совпадать, иначе будет выведено сообщение #Н/Д.
Выборочный r и популяционный ρ
Аналогично среднему значению и стандартному отклонению, коэффициент корреляции является сводной статистикой. Он описывает выборку; в данном случае, выборку спаренных значений: роста и веса. Коэффициент корреляции известной выборки обозначается буквой r, тогда как коэффициент корреляции неизвестной популяции обозначается греческой буквой ρ (рхо).
Как мы убедились в предыдущей серии постов о тестировании гипотез, мы не должны исходить из того, что результаты, полученные в ходе измерения нашей выборки, применимы к популяции в целом. К примеру, наша популяция может состоять из всех пловцов всех недавних Олимпийских игр. И будет совершенно недопустимо обобщать, например, на другие олимпийские виды спорта, такие как тяжелая атлетика или фитнес-плавание.
Даже в допустимой популяции — такой как пловцы, выступавшие на недавних Олимпийских играх, — наша выборка коэффициента корреляции является всего лишь одной из многих потенциально возможных. То, насколько мы можем доверять нашему r, как оценке параметра ρ, зависит от двух факторов:
-
Размера выборки
-
Величины r
Безусловно, чем больше выборка, тем больше мы ей доверяем в том, что она представляет всю совокупность в целом. Возможно, не совсем интуитивно очевидно, но величина тоже оказывает влияние на степень нашей уверенности в том, что выборка представляет параметр . Это вызвано тем, что большие коэффициенты вряд ли возникли случайным образом или вследствие случайной ошибки при отборе.
Проверка статистических гипотез
В предыдущей серии постов мы познакомились с проверкой статистических гипотез, как средством количественной оценки вероятности, что конкретная гипотеза (как, например, что две выборки взяты из одной и той же популяции) истинная. Чтобы количественно оценить вероятность, что корреляция существует в более широкой популяции, мы воспользуемся той же самой процедурой.
В первую очередь, мы должны сформулировать две гипотезы, нулевую гипотезу и альтернативную:
H — это гипотеза, что корреляция в популяции нулевая. Другими словами, наше консервативное представление состоит в том, что измеренная корреляция целиком вызвана случайной ошибкой при отборе.
H1 — это альтернативная возможность, что корреляция в популяции не нулевая. Отметим, что мы не определяем направление корреляции, а только что она существует. Это означает, что мы выполняем двустороннюю проверку.
Стандартная ошибка коэффициента корреляции r по выборке задается следующей формулой:
Эта формула точна, только когда r находится близко к нулю (напомним, что величина ρ влияет на нашу уверенность), но к счастью, это именно то, что мы допускаем согласно нашей нулевой гипотезы.
Мы можем снова воспользоваться t-распределением и вычислить t-статистику:
В приведенной формуле df — это степень свободы наших данных. Для проверки корреляции степень свободы равна n — 2, где n — это размер выборки. Подставив это значение в формулу, получим:
В итоге получим t-значение 102.21. В целях его преобразования в p-значение мы должны обратиться к t-распределению. Библиотека scipy предоставляет интегральную функцию распределения (ИФР) для t-распределения в виде функции , и комплементарной ей (1-cdf) функции выживания . Значение функции выживания соответствует p-значению для односторонней проверки. Мы умножаем его на 2, потому что выполняем двустороннюю проверку:
P-значение настолько мало, что в сущности равно 0, означая, что шанс, что нулевая гипотеза является истинной, фактически не существует. Мы вынуждены принять альтернативную гипотезу о существовании корреляции.
Что такое корреляция простыми словами
Не хочу вас сразу грузить формулами и расчётами, об этом поговорим ближе к концу. Давайте сначала разберемся, что по своей сути означает цифра коэффициента корреляции, которую вы можете встретить в какой-нибудь книге или статье.
Значение коэффициента может меняться от -1 до +1:
Если значение близко к единице или минус единице — значит два явления так или иначе сильно взаимосвязаны. Впрочем, причины этого не всегда очевидны — явление А может влиять на явление B, может быть наоборот. Нередко бывает, что существует явление C, которое приводит в движение А и В одновременно. В общем, природа корреляции — это уже второй вопрос, которым должны заниматься исследователи.
Околонулевые значения, в свою очередь, говорят об отсутствии какой-либо зависимости между явлениями. Нет конкретного предела, где заканчивается случайность и начинается взаимосвязь, все зависит от предмета исследования и количества данных. Навскидку, обычно при значениях от -0.3 до 0.3 можно говорить о том, что зависимость отсутствует.
При высокой положительной корреляции вслед за графиком А растёт и график B, и чем выше значение, тем слаженнее оба движутся. Для наглядности, вот как выглядит корреляция +1:

Движения графиков полностью повторяют друг друга, причем это как в случае простого добавления, так и с множителем.
При сильной отрицательной корреляции рост графика А приводит к падению графика B и наоборот. Вот так выглядит корреляция -1:

Движения графиков похожи на зеркальные отражения.
Коэффициент корреляции — удобный инструмент для анализа во многих сферах науки и жизни. Его легко рассчитать в Excel и применить, поэтому самая большая сложность в работе с ним — грамотно подобрать данные для расчёта. Основное правило — чем больше данных, тем лучше. Многие взаимосвязи проявляют себя лишь на длинной дистанции.
Также нужно следить за тем, чтобы найденные корреляции не были ложными.
Разбор результатов анализа
Результаты регрессионного анализа выводятся в виде таблицы в том месте, которое указано в настройках.

Одним из основных показателей является R-квадрат. В нем указывается качество модели. В нашем случае данный коэффициент равен 0,705 или около 70,5%. Это приемлемый уровень качества. Зависимость менее 0,5 является плохой.
Ещё один важный показатель расположен в ячейке на пересечении строки «Y-пересечение» и столбца «Коэффициенты». Тут указывается какое значение будет у Y, а в нашем случае, это количество покупателей, при всех остальных факторах равных нулю. В этой таблице данное значение равно 58,04.
Значение на пересечении граф «Переменная X1» и «Коэффициенты» показывает уровень зависимости Y от X. В нашем случае — это уровень зависимости количества клиентов магазина от температуры. Коэффициент 1,31 считается довольно высоким показателем влияния.
Как видим, с помощью программы Microsoft Excel довольно просто составить таблицу регрессионного анализа. Но, работать с полученными на выходе данными, и понимать их суть, сможет только подготовленный человек.
Мы рады, что смогли помочь Вам в решении проблемы.
Помогла ли вам эта статья?
Метод линейной регрессии позволяет нам описывать прямую линию, максимально соответствующую ряду упорядоченных пар (x, y). Уравнение для прямой линии, известное как линейное уравнение, представлено ниже:
ŷ — ожидаемое значение у при заданном значении х,
x — независимая переменная,
a — отрезок на оси y для прямой линии,
b — наклон прямой линии.
На рисунке ниже это понятие представлено графически:
На рисунке выше показана линия, описанная уравнением ŷ =2+0.5х. Отрезок на оси у — это точка пересечения линией оси у; в нашем случае а = 2. Наклон линии, b, отношение подъема линии к длине линии, имеет значение 0.5. Положительный наклон означает, что линия поднимается слева направо. Если b = 0, линия горизонтальна, а это значит, что между зависимой и независимой переменными нет никакой связи. Иными словами, изменение значения x не влияет на значение y.
Часто путают ŷ и у. На графике показаны 6 упорядоченных пар точек и линия, в соответствии с данным уравнением
На этом рисунке показана точка, соответствующая упорядоченной паре х = 2 и у = 4
Обратите внимание, что ожидаемое значение у в соответствии с линией при х
= 2 является ŷ. Мы можем подтвердить это с помощью следующего уравнения:
ŷ = 2 + 0.5х =2 +0.5(2) =3.
Значение у представляет собой фактическую точку, а значение ŷ — это ожидаемое значение у с использованием линейного уравнения при заданном значении х.
Следующий шаг — определить линейное уравнение, максимально соответствующее набору упорядоченных пар, об этом мы говорили в предыдущей статье, где определяли вид уравнения по методу наименьших квадратов.
Суть корреляционного анализа
Предназначение корреляционного анализа сводится к выявлению наличия зависимости между различными факторами. То есть, определяется, влияет ли уменьшение или увеличение одного показателя на изменение другого.
Если зависимость установлена, то определяется коэффициент корреляции. В отличие от регрессионного анализа, это единственный показатель, который рассчитывает данный метод статистического исследования. Коэффициент корреляции варьируется в диапазоне от +1 до -1. При наличии положительной корреляции увеличение одного показателя способствует увеличению второго. При отрицательной корреляции увеличение одного показателя влечет за собой уменьшение другого. Чем больше модуль коэффициента корреляции, тем заметнее изменение одного показателя отражается на изменении второго. При коэффициенте равном 0 зависимость между ними отсутствует полностью.
Корреляция и диверсификация
Как знания о корреляции активов могут помочь лучше вкладывать деньги? Думаю, вы все хорошо знакомы с золотым правилом инвестора — не клади все яйца в одну корзину. Речь, естественно, идёт о диверсификации инвестиционных активов в портфеле. Корреляция и диверсификация неразрывно связаны, что понятно даже из названия — английское diversify означает «разнообразить», а как коэффициент корреляции как раз показывает схожесть или различие двух явлений.
Другими словами, инвестировать в финансовые инструменты с высокой корреляцией не очень хорошо. Почему? Все просто — похожие активы плохо диверсифицируются. Вот пример портфеля двух активов с корреляцией +1:

Как видите, график портфеля во всех деталях повторяет графики каждого из активов — рост и падение обоих активов синхронны. Диверсификация в теории должна снижать инвестиционные риски за счёт того, что убытки одного актива перекрываются за счёт прибыли другого, но здесь этого не происходит совершенно. Все показатели просто усредняются:

Портфель даёт небольшой выигрыш в снижении рисков — но только по сравнению с более доходным Активом 1. А так, никаких преимуществ по сути нет, нам лучше просто вложить все деньги в Актив 1 и не париться.
А вот пример портфеля двух активов с корреляцией близкой к 0:

Где-то графики следуют друг за другом, где-то в противоположных направлениях, какой-либо однозначной связи не наблюдается. И вот здесь диверсификация уже работает:

Мы видим заметное снижение СКО, а значит портфель будет менее волатильным и более стабильно расти. Также видим небольшое снижение максимальной просадки, особенно если сравнивать с Активом 1. Инвестиционные инструменты без корреляции достаточно часто встречаются и из них имеет смысл составлять портфель.
Впрочем, это не предел. Наиболее эффективный инвестиционный портфель можно получить, используя активы с корреляцией -1:

Уже знакомое вам «зеркало» позволяет довести показатели риска портфеля до минимальных:
Несмотря на то, что каждый из активов обладает определенным риском, портфель получился фактически безрисковым. Какая-то магия, не правда ли? Очень жаль, но на практике такого не бывает, иначе инвестирование было бы слишком лёгким занятием.
Пример применения метода корреляционного анализа
В Великобритании было предпринято любопытное исследование. Оно посвящено связи курения с раком легких, и проводилось путем корреляционного анализа. Это наблюдение представлено ниже.
Исходные данные для корреляционного анализа
| Профессиональная группа | смертность |
| Фермеры, лесники и рыбаки | |
| Шахтеры и работники карьеров | |
| Производители газа, кокса и химических веществ | |
| Изготовители стекла и керамики | |
| Работники печей, кузнечных, литейных и прокатных станов | |
| Работники электротехники и электроники | |
| Инженерные и смежные профессии | |
| Деревообрабатывающие производства | |
| Кожевенники | |
| Текстильные рабочие | |
| Изготовители рабочей одежды | |
| Работники пищевой, питьевой и табачной промышленности | |
| Производители бумаги и печати | |
| Производители других продуктов | |
| Строители | |
| Художники и декораторы | |
| Водители стационарных двигателей, кранов и т. д. | |
| Рабочие, не включенные в другие места | |
| Работники транспорта и связи | |
| Складские рабочие, кладовщики, упаковщики и работники разливочных машин | |
| Канцелярские работники | |
| Продавцы | |
| Работники службы спорта и отдыха | |
| Администраторы и менеджеры | |
| Профессионалы, технические работники и художники |
Начинаем корреляционный анализ. Решение лучше начинать для наглядности с графического метода, для чего построим диаграмму рассеивания (разброса).

Она демонстрирует прямую связь. Однако на основании только графического метода сделать однозначный вывод сложно. Поэтому продолжим выполнять корреляционный анализ. Пример расчета коэффициента корреляции представлен ниже.
С помощью программных средств (на примере MS Excel будет описано далее) определяем коэффициент корреляции, который составляет 0,716, что означает сильную связь между исследуемыми параметрами. Определим статистическую достоверность полученного значения по соответствующей таблице, для чего нам нужно вычесть из 25 пар значений 2, в результате чего получим 23 и по этой строке в таблице найдем r критическое для p=0,01 (поскольку это медицинские данные, здесь используется более строгая зависимость, в остальных случаях достаточно p=0,05), которое составляет 0,51 для данного корреляционного анализа. Пример продемонстрировал, что r расчетное больше r критического, значение коэффициента корреляции считается статистически достоверным.
Что такое коэффициент корреляции?
Различные признаки могут быть связаны между собой.Выделяют 2 вида связи между ними:
- функциональная;
- корреляционная.
Корреляция в переводе на русский язык – не что иное, как связь. В случае корреляционной связи прослеживается соответствие нескольких значений одного признака нескольким значениям другого признака. В качестве примеров можно рассмотреть установленные корреляционные связи между:
- длиной лап, шеи, клюва у таких птиц как цапли, журавли, аисты;
- показателями температуры тела и частоты сердечных сокращений.
Для большинства медико-биологических процессов статистически доказано присутствие этого типа связи.
Статистические методы позволяют установить факт существования взаимозависимости признаков. Использование для этого специальных расчетов приводит к установлению коэффициентов корреляции (меры связанности).
Такие расчеты получили название корреляционного анализа. Он проводится для подтверждения зависимости друг от друга 2-х переменных (случайных величин), которая выражается коэффициентом корреляции.
Использование корреляционного метода позволяет решить несколько задач:
- выявить наличие взаимосвязи между анализируемыми параметрами;
- знание о наличии корреляционной связи позволяет решать проблемы прогнозирования. Так, существует реальная возможность предсказывать поведение параметра на основе анализа поведения другого коррелирующего параметра;
- проведение классификации на основе подбора независимых друг от друга признаков.
Для переменных величин:
- относящихся к порядковой шкале, рассчитывается коэффициент Спирмена;
- относящихся к интервальной шкале – коэффициент Пирсона.
Это наиболее часто используемые параметры, кроме них есть и другие.
Значение коэффициента может выражаться как положительным, так и отрицательными.
В первом случае при увеличении значения одной переменной наблюдается увеличение второй. При отрицательном коэффициенте – закономерность обратная.
Коэффициент парной корреляции в Excel
Разберем, как правильно проводить коэффициент парной корреляции в табличном процессоре Excel.
Расчет коэффициента парной корреляции в Excel
К примеру, у вас есть значения величин х и у.
12
Х – это зависимая переменна, а у – независимая. Необходимо найти направление и силу связи между этими показателями. Пошаговая инструкция:
- Выявим средние показатели величин при помощи функции СРЗНАЧ.
13
- Произведем расчет каждого х и хсредн, у и усредн при помощи оператора «-».
14
- Производим перемножение вычисленных разностей.
15
- Вычисляем сумму показателей в этом столбце. Числитель – найденный результат.
16
- Посчитаем знаменатели разницы х и х-средн, у и у-средн. Для этого произведем возведение в квадрат.
17
- Используя функцию АВТОСУММА, найдем показатели в полученных столбиках. Производим перемножение. При помощи функции КОРЕНЬ возводим результат в квадрат.
18
- Производим подсчет частного, используя значения знаменателя и числителя.
1920
- КОРРЕЛ – интегрированная функция, которая позволяет предотвратить проведение сложнейших расчетов. Заходим в «Мастер функций», выбираем КОРРЕЛ и указываем массивы показателей х и у. Строим график, отображающий полученные значения.
21
Матрица парных коэффициентов корреляции в Excel
Разберем, как проводить подсчет коэффициентов парных матриц. К примеру, есть матрица из четырех переменных.
22
Пошаговая инструкция:
- Заходим в «Анализ данных», находящийся в блоке «Анализ» вкладки «Данные». В отобразившемся списке выбираем «Корелляция».
- Выставляем все необходимые настройки. «Входной интервал» – интервал всех четырех колонок. «Выходной интервал» – место, в котором желаем отобразить итоги. Кликаем на кнопку «ОК».
- В выбранном месте построилась матрица корреляции. Каждое пересечение строки и столбца – коэффициенты корреляции. Цифра 1 отображается при совпадающих координатах.
23
Как проводится корреляционный анализ в Excel
Суть данного анализа сводится к выявлению зависимостей между различными факторами, представленными в таблицах. Таким образом можно определить как повлияет уменьшение или увеличение определенных показателей на исследуемые данные.
Если была выявлена зависимость, то определяется уже коэффициент корреляции. Коэффициент будет варьироваться в значениях от -1 до +1. При положительной корреляции, увеличение одного показателя повлечет за собой увеличение другого. Соответственно при отрицательной будет уменьшение. Чем больше значение корреляции, тем сильнее оказываемое влияние.
Для примера возьмем таблицу, где представлена прямая зависимость одних показателей от других. Например, зарплата сотрудников и величина прибыли компании. Далее рассмотрим два способа реализации корреляционного анализа на примере этой таблицы.
Вариант 1: Вызов через Мастер функций
В отличии от некоторых других типов анализов, корреляционный анализ можно вызвать с помощью функций. За него отвечает функция КОРРЕЛ вида: КОРРЕЛ(массив1;массив2):
- Выделите ячейку в таблицу, куда хотите вставить полученный результат. В строке ввода формул воспользуйтесь значком функции.

Откроется окно мастера функций. В поле “Категория” нужно поставить значение “Полный алфавитный перечень”, чтобы отобразились все доступные для применения функции. Там отыщите пункт “КОРРЕЛ” нажмите по нему и затем на кнопку “Ок”.</li>

Вам потребуется заполните в окошке настройки функции два поля, то есть указать два массива ячеек. В первый массив укажите номера ячеек, зависимость которых следует определить. Для рассматриваемой таблицы это будет массив столбца дохода компании. Номера можно вписать вручную или выделить их, кликнув по иконке таблицы в поле.</li>Во втором же массиве потребуется указать перечень ячеек, которые предположительно должны оказывать влияние на первый массив. В рассматриваемой таблице это величина зарплат сотрудников.</li>

Закончив с заполнением нажмите кнопку “Ок”. Подсчет будет произведен автоматически и выведен в указанной ранее ячейке.</li>Если полученный коэффициент оказался больше +/-0.5, то это значит, что одна величина сильно зависима от другой.</li> </ol>
</ol>
Вариант 2: Применение пакета анализа
Вы можете использовать уже заданный шаблон корреляционного анализа, используя один из представленных пакетов анализа. По умолчанию пакеты анализа в Excel отключены, поэтому вам потребуется их включать отдельно.
- Перейдите во вкладку “Файл”, что расположена в верхней части окна.

В левой части переключитесь в раздел “Параметры”.</li>Откройте подраздел “Надстройки”, что находятся в левой части окна с параметрами.</li>У строки “Управление”, что расположена в нижней части открывшегося окна, установите значение “Надстройки Excel”. Нажмите “Перейти”, чтобы увидеть перечень доступных надстроек.</li>

В открывшемся окне установите галочку у пункта “Пакет анализа” и нажмите “Ок”. После этого у вас должны появится дополнительные инструменты в верхней панели Excel.</li>Нужные нам инструменты расположена во вклакде “Данные”. Там должен будет появится дополнительный блок инструментов — “Анализ”. Воспользуйтесь в нем единственным инструментом — “Анализом данных”.</li>

Открывается список с различными вариантами анализа данных. Укажите пункт “Корреляция”. Нажмите “Ок” для применения.</li>В открывшемся окошке настройки анализа уже потребуется заполнить только поле “Входной интервал”. Туда добавляется сразу два массива. В нашем случае это столбцы с зарплатой и доходом фирмы.</li>В блоке ниже можно указать, куда будет выводится результат. По умолчанию он выводит на новый рабочий лист, но вы можете настроить вывод в новую книгу или в определенных ячейках на текущем листе. Нажмите для применения и расчетов.</li>В итоге вы получите тот же результат, что и в первом способе. Единственное, в некоторых таблицах, при обработке большего количества данных значений может быть гораздо больше (в основном носят вспомогательный характер).</li></ol>
Первый рассмотренный нами способ подойдет для большинства таблиц, в то время как второй больше подходит для таблиц с большим перечнем данных, где еще желательно отследить логику проводимого анализа.
- https://lumpics.ru/correlation-analysis-in-excel/
- https://mir-tehnologiy.ru/korrelyatsiya-v-excel/
- https://exceltable.com/funkcii-excel/primery-funkcii-korrel
- https://public-pc.com/korrelyaczionnyj-analiz-v-excel/
Как вы можете рассчитать корреляцию с помощью Excel? — 2019
a:
Корреляция измеряет линейную зависимость двух переменных. Измеряя и связывая дисперсию каждой переменной, корреляция дает представление о силе взаимосвязи. Или, говоря иначе, корреляция отвечает на вопрос: сколько переменная A (независимая переменная) объясняет переменную B (зависимую переменную)?
Формула корреляции
Корреляция объединяет несколько важных и связанных статистических понятий, а именно дисперсию и стандартное отклонение. Разница — дисперсия переменной вокруг среднего, а стандартное отклонение — квадратный корень дисперсии.
Формула:
Поскольку корреляция требует оценки линейной зависимости двух переменных, то, что действительно необходимо, — это выяснить, какая сумма ковариации этих двух переменных и в какой степени такая ковариация отраженные стандартными отклонениями каждой переменной в отдельности.
Общие ошибки с корреляцией
Самая распространенная ошибка — предполагать, что корреляция, приближающаяся +/- 1, статистически значима. Считывание, приближающееся +/- 1, безусловно увеличивает шансы на фактическую статистическую значимость, но без дальнейшего тестирования это невозможно узнать.
Статистическое тестирование корреляции может усложняться по ряду причин; это совсем не так просто. Критическое предположение о корреляции состоит в том, что переменные независимы и связь между ними является линейной.
Вторая наиболее распространенная ошибка — забыть нормализовать данные в единую единицу. Если вычислять корреляцию по двум бетам, то единицы уже нормализованы: сама бета является единицей
Однако, если вы хотите скорректировать акции, важно, чтобы вы нормализовали их в процентном отношении, а не изменяли цены. Это происходит слишком часто, даже среди профессионалов в области инвестиций
Для корреляции цен на акции вы, по сути, задаете два вопроса: каково возвращение за определенное количество периодов и как этот доход коррелирует с возвратом другой безопасности за тот же период? Это также связано с тем, что корреляция цен на акции затруднена: две ценные бумаги могут иметь высокую корреляцию, если доход составляет ежедневно процентов за последние 52 недели, но низкая корреляция, если доход ежемесячно > изменения за последние 52 недели. Какая из них лучше»? На самом деле нет идеального ответа, и это зависит от цели теста. ( Улучшите свои навыки excel, пройдя курс обучения Excel в Академии Excel. ) Поиск корреляции в Excel
Существует несколько методов расчета корреляции в Excel
Самый простой способ — получить два набора данных и использовать встроенную формулу корреляции:
Это удобный способ расчета корреляции между двумя наборами данных. Но что, если вы хотите создать корреляционную матрицу во множестве наборов данных? Для этого вам нужно использовать плагин анализа данных Excel. Плагин можно найти на вкладке «Данные» в разделе «Анализ».
Выберите таблицу возвратов. В этом случае наши столбцы имеют названия, поэтому мы хотим установить флажок «Ярлыки в первой строке», поэтому Excel знает, как обрабатывать их как заголовки. Затем вы можете выбрать вывод на том же листе или на новом листе.
Как только вы нажмете enter, данные будут автоматически сделаны. Вы можете добавить текст и условное форматирование, чтобы очистить результат.
Как рассчитать коэффициент корреляции в Excel
В сегодняшней статье речь пойдет о том, как переменные могут быть связаны друг с другом. С помощью корреляции мы сможем определить, существует ли связь между первой и второй переменной. Надеюсь, это занятие покажется вам не менее увлекательным, чем предыдущие!
Корреляция измеряет мощность и направление связи между x и y. На рисунке представлены различные типы корреляции в виде графиков рассеяния упорядоченных пар (x, y). По традиции переменная х размещается на горизонтальной оси, а y — на вертикальной.
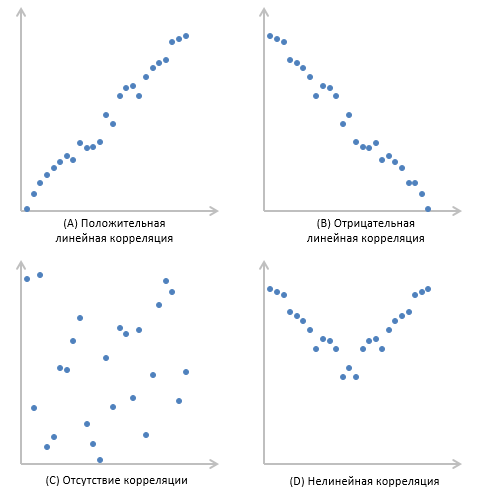
График А являет собой пример положительной линейной корреляции: при увеличении х также увеличивается у, причем линейно. График В показывает нам пример отрицательной линейной корреляции, на котором при увеличении х у линейно уменьшается. На графике С мы видим отсутствие корреляции между х и у. Эти переменные никоим образом не влияют друг на друга.
Наконец, график D — это пример нелинейных отношений между переменными. По мере увеличения х у сначала уменьшается, потом меняет направление и увеличивается.
Оставшаяся часть статьи посвящена линейным взаимосвязям между зависимой и независимой переменными.
Коэффициент корреляции
Коэффициент корреляции, r, предоставляет нам как силу, так и направление связи между независимой и зависимой переменными. Значения r находятся в диапазоне между — 1.0 и + 1.0. Когда r имеет положительное значение, связь между х и у является положительной (график A на рисунке), а когда значение r отрицательно, связь также отрицательна (график В). Коэффициент корреляции, близкий к нулевому значению, свидетельствует о том, что между х и у связи не существует график С).
Сила связи между х и у определяется близостью коэффициента корреляции к — 1.0 или +- 1.0. Изучите следующий рисунок.
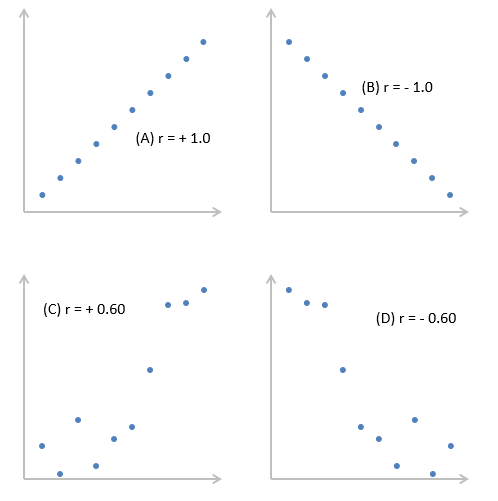
График A показывает идеальную положительную корреляцию между х и у при r = + 1.0. График В — идеальная отрицательная корреляция между х и у при r = — 1.0. Графики С и D — примеры более слабых связей между зависимой и независимой переменными.
Коэффициент корреляции, r, определяет, как силу, так и направление связи между зависимой и независимой переменными. Значения r находятся в диапазоне от — 1.0 (сильная отрицательная связь) до + 1.0 (сильная положительная связь). При r= 0 между переменными х и у нет никакой связи.
Мы можем вычислить фактический коэффициент корреляции с помощью следующего уравнения:
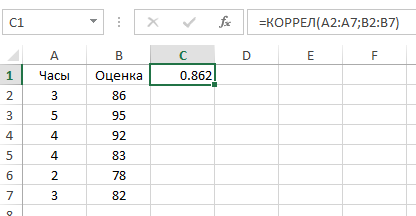
Ну и ну! Я знаю, что выглядит это уравнение как страшное нагромождение непонятных символов, но прежде чем ударяться в панику, давайте применим к нему пример с экзаменационной оценкой. Допустим, я хочу определить, существует ли связь между количеством часов, посвященных студентом изучению статистики, и финальной экзаменационной оценкой. Таблица, представленная ниже, поможет нам разбить это уравнение на несколько несложных вычислений и сделать их более управляемыми.
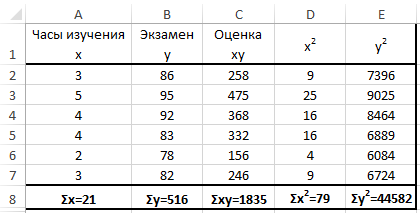
Как видите, между числом часов, посвященных изучению предмета, и экзаменационной оценкой существует весьма сильная положительная корреляция. Преподаватели будут весьма рады узнать об этом.
Какова выгода устанавливать связь между подобными переменными? Отличный вопрос. Если обнаруживается, что связь существует, мы можем предугадать экзаменационные результаты на основе определенного количества часов, посвященных изучению предмета. Проще говоря, чем сильнее связь, тем точнее будет наше предсказание.
Использование Excel для вычисления коэффициентов корреляции
Я уверен, что, взглянув на эти ужасные вычисления коэффициентов корреляции, вы испытаете истинную радость, узнав, что программа Excel может выполнить за вас всю эту работу с помощью функции КОРРЕЛ со следующими характеристиками:
КОРРЕЛ (массив 1; массив 2),
массив 1 = диапазон данных для первой переменной,
массив 2 = диапазон данных для второй переменной.
Например, на рисунке показана функция КОРРЕЛ, используемая при вычислении коэффициента корреляции для примера с экзаменационной оценкой.